이번 포스팅에서는 웹 스크래핑(web scraping)에서 많이 사용되는 라이브러리인 beautifulsoup의 기본적인 사용법에 대해 소개해드리려고합니다.
시작해볼까요?😎
1. 웹 스크래핑
웹 스크래핑(Web Scraping)은 웹사이트에서 필요한 공개된 데이터를 자동으로 수집하는 기술을 의미합니다. 웹 스크래핑을 통해 우리는 특정 웹사이트에서 원하는 정보를 추출하고 분석할 수 있습니다.
1.1 웹 스크래핑 예시
실제 웹 스크래핑을 이용한 사이트의 예시를 볼까요?
가격 비교 서비스
전자 상거래 사이트에서 상품의 가격 정보를 수집하여 소비자에게 가격 비교 서비스를 제공하는 대표적인 예가 있습니다. 여러 쇼핑몰에서 동일한 상품의 가격을 스크래핑하여 한 곳에서 비교할 수 있게 해주는 것이 목적입니다. 부동산 매물 정보 수집
부동산 거래 플랫폼에서 매물의 가격, 위치, 크기 등의 정보를 스크래핑하여 데이터를 분석하거나 시각화에 활용합니다.
1.2 웹 스크래핑의 단계
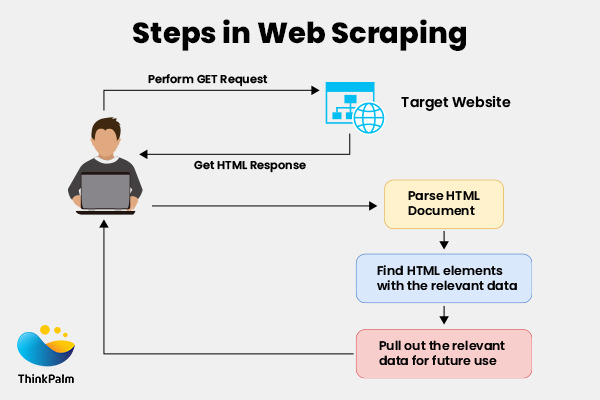
웹 스크래핑은 requests라이브러리로 HTTP GET Requests를 원하는 웹사이트에 보낸 후, HTML Response를 받게됩니다. (requests라이브러리에 대한 개념과 HTTP request에 대한 개념은 이전 글을 참고하시기바랍니다: [웹스크래핑] 파이썬 Requests 라이브러리) 이때 받은 HTML Response를 파싱(parsing)하는 것이 Beautifulsoup 라이브러리입니다.
HTML parsing이 뭘까요?🤔
1.3 HTML parsing이란?
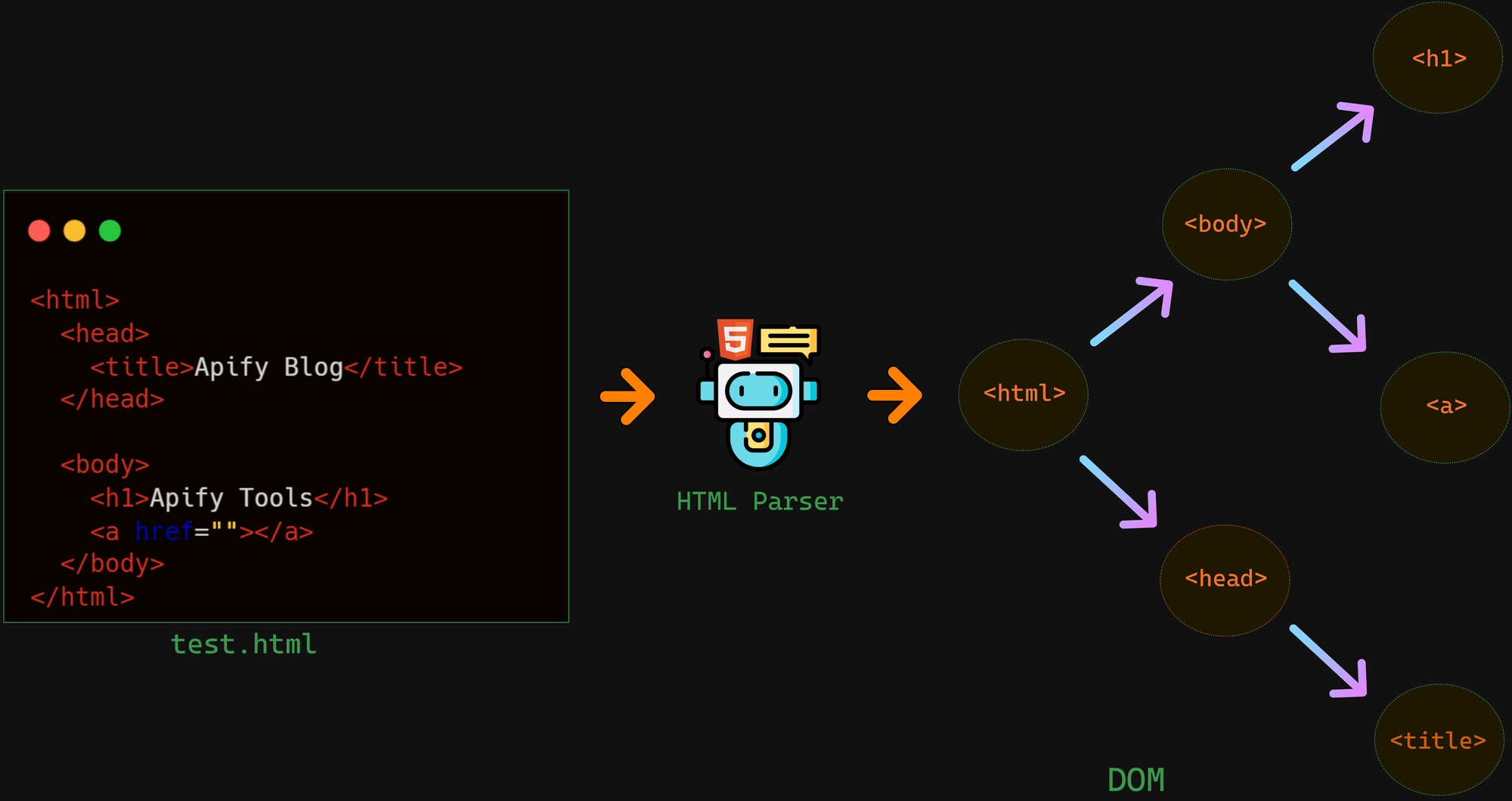
HTML 파싱은 웹 브라우저나 프로그램이HTML 문서를 읽고 해석하여 구조화된 형태로 변환하는 과정입니다. 이 과정을 통해 HTML의 요소들(태그, 속성, 텍스트 등)을 프로그램이 처리할 수 있도록 정리하고 조작할 수 있습니다.
그럼 이런 궁금증이 생길 수 있습니다.
그래서 왜 HTML parsing을 해야하는건가요? 그냥 requests 라이브러리로 요청받아서 사용하면 안되나요?
이제 html 파싱을 해야하는 이유에 대해 알아보겠습니다.🤔
1.3.1 HTML parsing을 하는 이유
requests 라이브러리는 HTTP 요청을 통해 웹 페이지의 HTML 소스 코드를 가져오는 역할을 합니다.
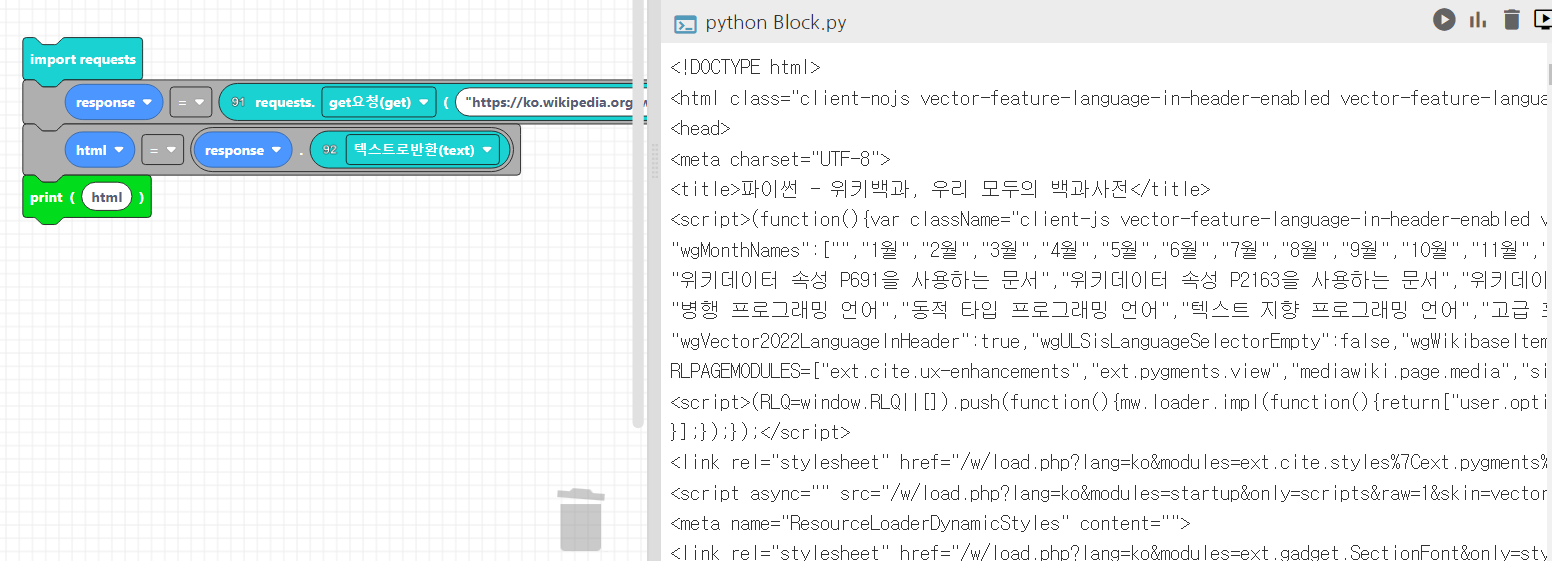
⭐예시)위키피디아의 파이썬 페이지를 requests라이브러리를 통해 GET요청으로 가지고와서 출력해보겠습니다.
코드웍스 블록으로 코딩해서 출력해본 결과, html 형식으로 출력된 것을 확인하실 수 있습니다.
HTML 소스 코드는 단순한 문자열로 구성된 원시 데이터에 불과합니다. 이러한 데이터를 구조적으로 이해하거나 원하는 정보만 효율적으로 추출하려면 HTML Parsing이 필요합니다.
HTML 파싱의 주요 목적
HTML 구조 분석: 웹 페이지의 DOM(Document Object Model) 구조를 이해하기 위함.
데이터 추출: HTML 문서에서 필요한 정보를 추출(웹 스크래핑)하거나 데이터를 변환하기 위함.
HTML 조작: HTML 문서를 수정하거나 동적으로 콘텐츠를 추가하는 작업을 지원.
이제 웹스크래핑에서 html 파싱에 사용되는 라이브러리인 beautifulsoup에 대해 알아보겠습니다.🧐
2. BeautifulSoup
2.1 BeautifulSoup이란
BeautifulSoup은 Python에서 HTML과 XML 문서를 쉽게 파싱할 수 있도록 돕는 라이브러리입니다. 이 라이브러리는 다양한 HTML 파서를 지원하며, 간단하고 직관적인 API를 제공합니다.
HTML과 XML 문서 파싱 가능
유연한 탐색 및 데이터 추출
계층적 DOM 트리 분석
다양한 파서 지원: html.parser, lxml, html5lib 등
2.2 설치
코드웍스에서는 BeautifulSoup와 request 라이브러리를 제공하기때문에, 설치가 따로 필요없습니다.
개인 로컬 컴퓨터에서 실습을 할 시에는 설치가 필요합니다. 설치는 터미널에서 다음 명령어를 실행하면 됩니다.
pip install beautifulsoup4
pip install requests
3. BeautifulSoup 기본 사용법
3.1 HTML 가져오기
웹 페이지의 HTML 코드를 가져오려면 requests 라이브러리와 BeautifulSoup을 함께 사용합니다.
3.1.1 라이브러리 임포트
import requests
from bs4 import BeautifulSoup
3.1.2 웹페이지 가져오기
웹페이지를 가지고 오려면 request 라이브러리를 활용해서 GET요청을 보내 html을 받아옵니다. requests라이브러리에 대한 설명은 이전 포스트 [웹스크래핑] 파이썬 Requests 라이브러리를 참고하시면 됩니다.
HTTP status_code를 받아와서, 200이면 성공, 아니면 실패로 출력하도록 하였습니다.
GET요청을 통해 html을 데이터를 받아와서 텍스트로 변환해서 html 변수에 저장하였습니다.
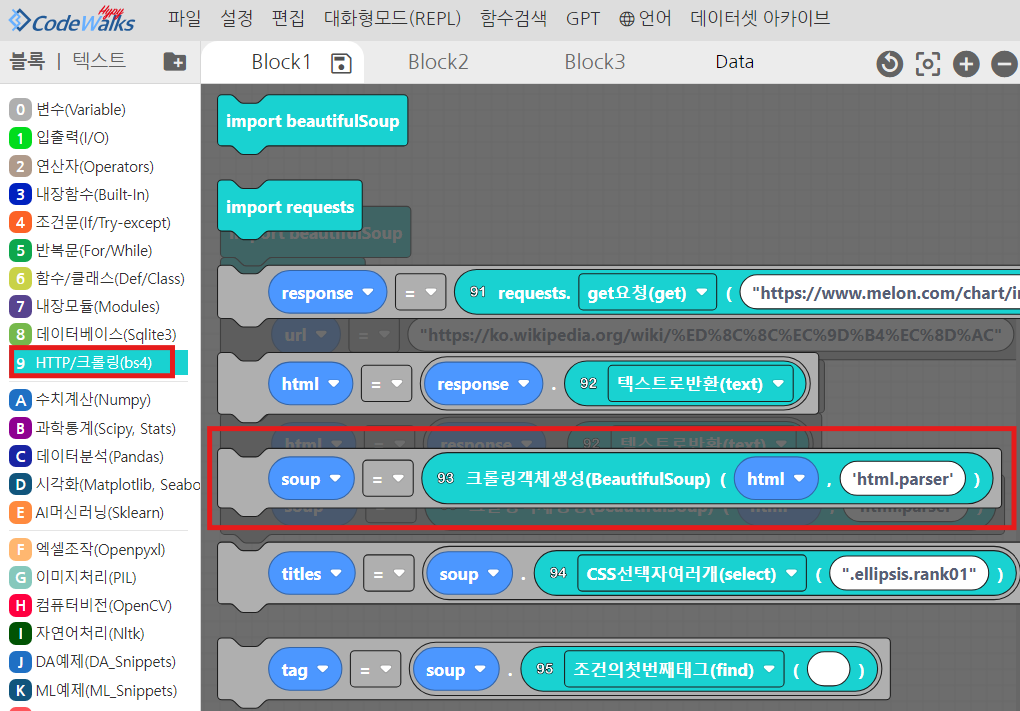
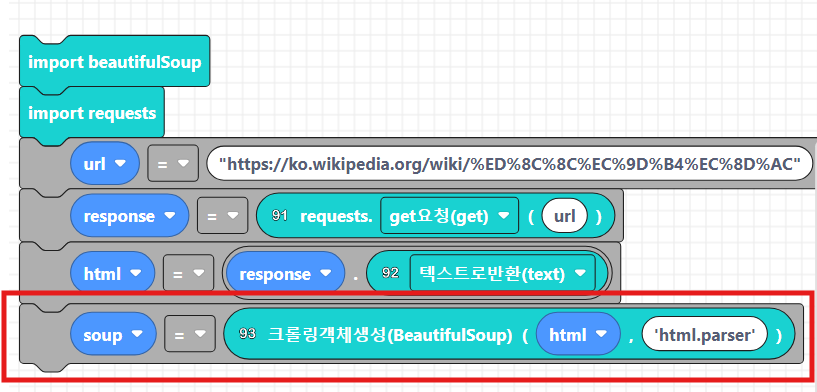
url = "https://ko.wikipedia.org/wiki/파이썬"
response = requests.get(url)
html = response.text
# 상태 코드 확인
if response.status_code == 200:
print("페이지 접근 성공")
else:
print("페이지 접근 실패")
이제 이 텍스트로 변환한 html 데이터를 파싱해보도록 하겠습니다.
3.1.3 BeautifulSoup 객체 생성
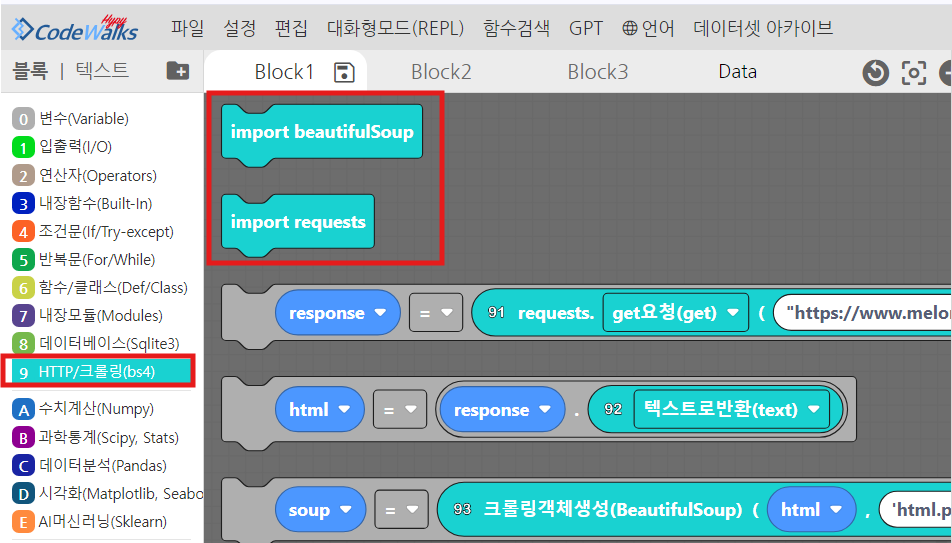
html 파싱은 beautifulsoup을 사용하면 되는데요, 객체를 생성해서 'html.parser'를 사용합니다.
코드웍스에는 93번 블록에 있습니다.
# BeautifulSoup 객체 생성
soup = BeautifulSoup(response.text, 'html.parser')
3.2 HTML 구조 이해하기
웹 크롤링의 첫 단계는 HTML 구조를 이해하는 것입니다. HTML 문서는 기본적으로태그(tag)와속성(attribute)으로 구성됩니다. 웹 페이지의 HTML 구조를 이해하는 것은 데이터를 효과적으로 크롤링하기 위해 매우 중요합니다. 이제 HTML의 주요 태그와 속성을 살펴보겠습니다.
<!DOCTYPE html>
<html lang="en"> <!-- HTML5 문서 선언 및 언어 설정 -->
<head>
<meta charset="UTF-8"> <!-- 문서 인코딩 설정 -->
<meta name="viewport" content="width=device-width, initial-scale=1.0"> <!-- 반응형 웹 설정 -->
<title>HTML 주요 태그</title> <!-- 페이지 제목 -->
</head>
<body> <!-- 본문 콘텐츠 시작 -->
<header> <!-- 페이지의 머리글 -->
<h1>HTML 주요 태그</h1> <!-- 페이지 주요 제목 -->
</header>
<main> <!-- 주요 콘텐츠 영역 -->
<h2>제목과 문단</h2> <!-- 섹션 제목 -->
<p>HTML에서는 <code>h1</code>에서 <code>h6</code>까지 제목을 작성하며, 문단은 <code>p</code>로 작성합니다.</p> <!-- 문단 설명 -->
<h2>목록</h2> <!-- 목록 섹션 -->
<ul> <!-- 순서 없는 목록 -->
<li>순서 없는 목록</li> <!-- 목록 항목 -->
</ul>
<ol> <!-- 순서 있는 목록 -->
<li>순서 있는 목록</li>
</ol>
<h2>이미지</h2> <!-- 이미지 섹션 -->
<img src="example.jpg" alt="예시 이미지" width="100"> <!-- 이미지 삽입 (가로 100px) -->
<h2>테이블</h2> <!-- 테이블 섹션 -->
<table border="1"> <!-- 테두리가 있는 테이블 -->
<tr> <!-- 테이블 헤더 행 -->
<th>이름</th> <!-- 열 제목: 이름 -->
<th>나이</th> <!-- 열 제목: 나이 -->
<th>직업</th> <!-- 열 제목: 직업 -->
</tr>
<tr> <!-- 첫 번째 데이터 행 -->
<td>홍길동</td> <!-- 데이터: 이름 -->
<td>30</td> <!-- 데이터: 나이 -->
<td>개발자</td> <!-- 데이터: 직업 -->
</tr>
</table>
</main>
</body>
</html>
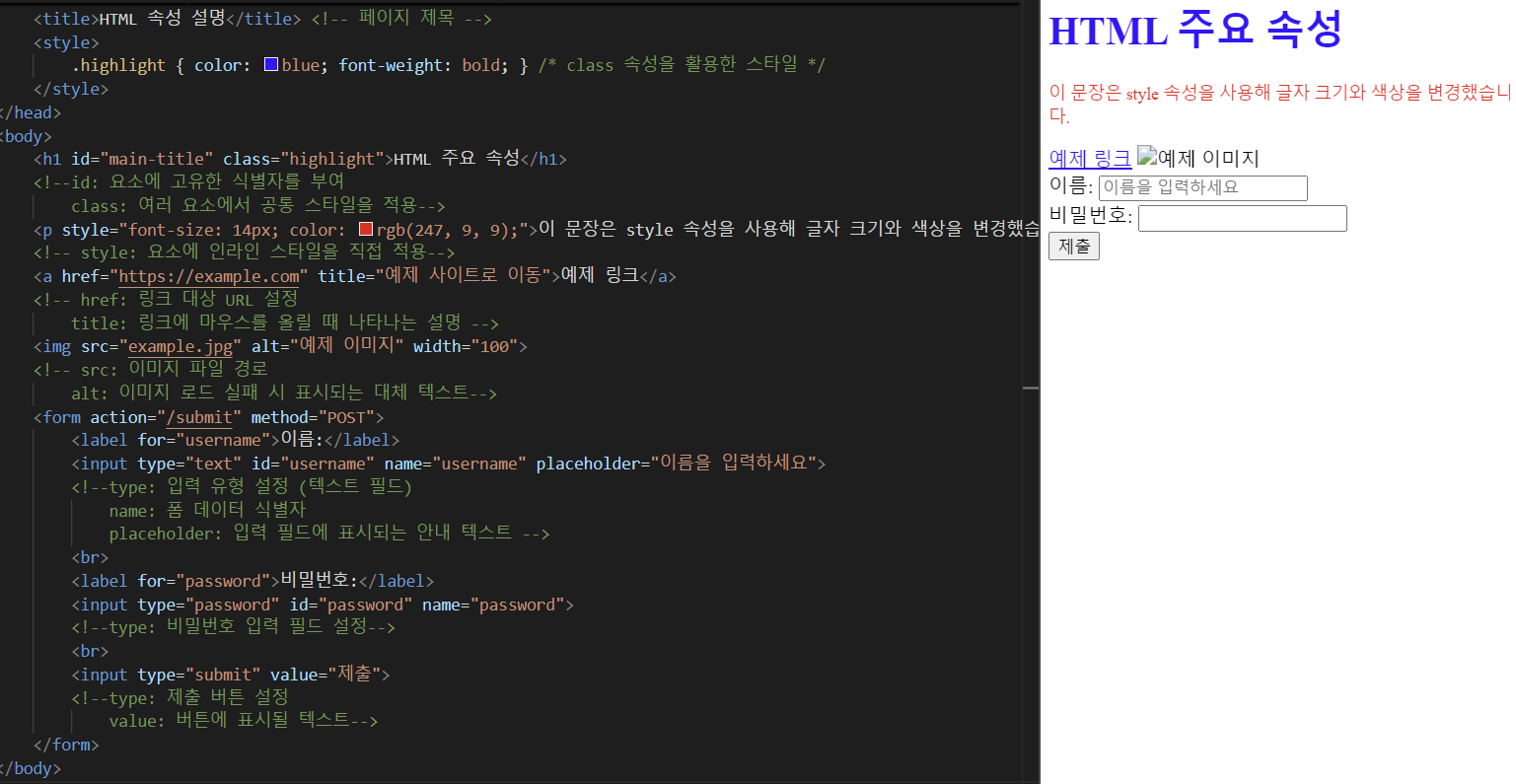
3.2.2 HTML 주요 속성
주요 속성들을 사용해서 html을 작성하였습니다. 여기서 사용된 코드는 접은글에 있습니다.
<!DOCTYPE html>
<html lang="en"> <!-- 문서 언어를 영어로 설정 -->
<head>
<meta charset="UTF-8"> <!-- 문자 인코딩 설정 -->
<meta name="viewport" content="width=device-width, initial-scale=1.0"> <!-- 반응형 웹 설정 -->
<title>HTML 속성 설명</title> <!-- 페이지 제목 -->
<style>
.highlight { color: blue; font-weight: bold; } /* class 속성을 활용한 스타일 */
</style>
</head>
<body>
<h1 id="main-title" class="highlight">HTML 주요 속성</h1>
<!--id: 요소에 고유한 식별자를 부여
class: 여러 요소에서 공통 스타일을 적용-->
<p style="font-size: 14px; color: rgb(247, 9, 9);">이 문장은 style 속성을 사용해 글자 크기와 색상을 변경했습니다.</p>
<!-- style: 요소에 인라인 스타일을 직접 적용-->
<a href="https://example.com" title="예제 사이트로 이동">예제 링크</a>
<!-- href: 링크 대상 URL 설정
title: 링크에 마우스를 올릴 때 나타나는 설명 -->
<img src="example.jpg" alt="예제 이미지" width="100">
<!-- src: 이미지 파일 경로
alt: 이미지 로드 실패 시 표시되는 대체 텍스트-->
<form action="/submit" method="POST">
<label for="username">이름:</label>
<input type="text" id="username" name="username" placeholder="이름을 입력하세요">
<!--type: 입력 유형 설정 (텍스트 필드)
name: 폼 데이터 식별자
placeholder: 입력 필드에 표시되는 안내 텍스트 -->
<br>
<label for="password">비밀번호:</label>
<input type="password" id="password" name="password">
<!--type: 비밀번호 입력 필드 설정-->
<br>
<input type="submit" value="제출">
<!--type: 제출 버튼 설정
value: 버튼에 표시될 텍스트-->
</form>
</body>
</html>
BeautifulSoup을 사용하면 이러한 태그에 쉽게 접근할 수 있습니다.
이제 다음포스팅에서는 다양한 beautifulsoup의 메서드들을 활용해서 원하는 데이터를 스크래핑 해보겠습니다.