
안녕하세요 코드웍스입니다.
이번시간에는 데이터분석을 할때 기본적으로 자주 사용되는 파이썬 라이브러리인 넘파이(numpy)를 이요해서 배열(array)을 생성하는 방법에 대해 다뤄보겠습니다. 😎
넘파이(numpy)란?

NumPy(Numerical Python)는 파이썬의 고성능 수치 계산을 위한 핵심 라이브러리입니다.
데이터 분석, 머신러닝, 과학 계산 등 다양한 분야에서 필수적으로 사용되는 도구로, 특히 대규모 배열과 행렬 연산을 효율적으로 처리할 수 있게 해줍니다.
왜 데이터분석에서 numpy가 사용될까? 🤔
- 속도와 메모리 효율성: 데이터 분석에서는 큰 데이터를 다루는 일이 많기 때문에, 메모리와 속도가 중요한데, NumPy는 일반적인 Python 리스트보다 훨씬 빠르게 연산을 수행하고 메모리 효율이 뛰어납니다.
- 다양한 기능 제공: 데이터 분석에 필요한 수학적 함수, 통계적 연산, 난수 생성 등 다양한 기능을 제공합니다.
- 다른 라이브러리와의 호환성: Pandas, SciPy, Matplotlib 등 데이터 분석에 널리 쓰이는 다른 라이브러리들이 NumPy 배열을 기반으로 하고 있어, 상호 호환이 뛰어납니다.
그럼 이번 포스팅에서 다룰 배열이란 뭘까요? 🤔
넘파이 배열(array)이란?

배열(array)은 동일한 자료형의 값을 담고 있는 다차원 데이터 구조입니다.
파이썬의 리스트와 비슷하지만, 모든 요소가 같은 자료형을 가져야 한다는 특징이 있습니다.
주요 특징
- 동일한 데이터 타입: 모든 원소가 같은 데이터 타입을 가져야 합니다.
- 연속된 메모리 할당: 배열은 메모리상 연속적으로 저장되므로 데이터 접근 속도가 빠릅니다.

- 다차원 지원: 1차원, 2차원(행렬), 3차원 이상의 고차원 배열을 만들 수 있습니다.
- 벡터화 연산 지원: 반복문을 사용하지 않고도 배열 전체에 연산을 적용할 수 있습니다. 이를 벡터화(vectorization)라고 하며, 코드를 더 효율적이고 간결하게 만들어줍니다. 😏
코드웍스에서 numpy 사용하기
블록코딩과 텍스트 드래그 코딩으로 데이터분석과 AI를 학습할 수 있는 플랫폼인 코드웍스에서는 A블록 수치계산에서 numpy의 기능을 모두 제공합니다! 😎
numpy를 사용하시기전 무조건 import를 먼저하셔야한다는점 잊지마세요!
import numpy as np

1. 리스트나 튜플로 배열 생성하기
가장 기본적인 numpy 배열 생성방법은 리스트나 튜플로 배열을 생성하는 방법입니다.
보통 일반적으로는 리스트 표현을 더 많이 사용하는 편입니다.
넘파이 배열 생성 코드웍스 코드는 아래 링크에서 사용하실 수 있습니다.
1.1 1차원 배열(vector) 생성
#리스트로 넘파이 배열 생성
arr = np.array([2, 4, 6, 8, 10])
print(arr)
print(type(arr))
#튜플로 넘파이 배열 생성
arr = np.array((2, 4, 6, 8, 10))
print(arr)
print(type(arr))코드웍스에서는 배열 생성 블록을 A1블록에서 제공합니다. 배열과 배열의 타입을 출력해보면, numpy.ndarray로 넘파이 배열이 생성된 것을 확인하실 수 있습니다.


이제 다차원 배열을 생성해보겠습니다.
1.2 2차원 배열(Matrix) 생성

2차원 배열은 행과 열로 구성됩니다.
#리스트로 2차원 배열 생성
arr = np.array([[1, 2, 3],[4, 5, 6]])
print("리스트로 2차원 배열 생성: \n", arr)
#튜플로 2차원 배열 생성
arr = np.array([(1,2,3),(4,5,6)])
print("튜플로 2차원 배열 생성: \n", arr)

1.3 3차원 배열 (Cube) 생성

3차원 배열은 여러 개의 2차원 배열을 쌓아 올린 형태로, 주로 [깊이, 행, 열]의 구조를 갖습니다. 아래 예시는 (2,2,2) 구조를 가진 3차원 배열의 예시입니다.
arr = np.array([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])
print("리스트로 3차원 배열 생성 \n", arr)
arr = np.array([[(1, 2), (3, 4)], [(5, 6), (7, 8)]])
print("튜플로 3차원 배열 생성 \n", arr)

2. 특정값으로 배열 생성하기
특정한 값으로 배열을 생성하는 것은 데이터 분석과 연산에서 중요한 역할을 합니다. 이제 특정한 값만으로 이루어진 배열을 생성하는 방법에 대해 소개해드리도록 하겠습니다. 😎
이 부분에 대한 코드웍스 코드는 아래 링크에 있습니다.
2.1 모든 요소가 0인 배열 생성
2.1.1 zeros()
원하는 크기와 데이터 타입을 넣으면 그 크기에 맞는 모든 요소가 0인 배열이 생성됩니다. 사용방법은 아래와 같습니다.
# shape: 원하는 shape // dtype: 기본값은 float
#np.zeros(shape, dtype=float)
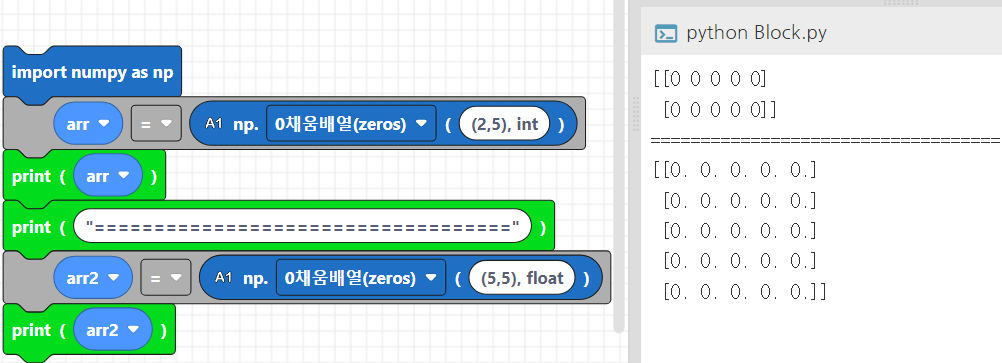
arr = np.zeros((2,5), int)
print(arr)
arr2 = np.zeros((5,5), float)
print(arr2)이를 출력해보면,

2.1.2 zeros_like()
zeros()는 배열의 크기와 dtype을 제시하고 생성했다면, zeros_like()는 기존 배열과 동일한 shape과 dtype을 가지면서 모든 요소가 0인 배열을 생성합니다. 즉 배열이 주어졌을때, 동일한 크기와 데이터타입을 가진 모든 요소가 0인 배열을 만들어주는 함수인 것입니다.
var = np.array([[1, 2], [3, 4]]) #array 생성
arr = np.zeros_like(var) #zeros_like로 var array와 같은 크기의 모든 요소가 0으로 이루어진 array 생성
print(arr)

2.2 모든 요소가 1인 배열 생성
2.2.1 ones()
arr = np.ones((3,5), int)
print(arr)
print("==========================")
arr2 = np.ones((5,5), float)
print(arr2)

2.2.2 ones_like()
기존 배열과 동일한 shape과 dtype을 가지면서 모든 요소가 1인 배열을 생성합니다.
var = np.array([[1,2],[3,4]])
arr = np.ones_like(var)
print(arr)

2.3 모든 요소가 특정 값으로 채워진 배열 생성
2.3.1 full()
모든 요소를 지정한 shape과 fill_value로 모든 요소가 특정 값으로 채워진 배열을 생성합니다.
#np.full(shape, fill_value, dtype=None)
arr = np.full((3,5), 5) #(3,5)크기의 array에 5를 채워넣어서 생성하기
print(arr)

2.3.2 full_like()
기존 배열과 동일한 shape과 dtype을 가지면서 모든 요소가 특정 값으로 채워진 배열을 생성합니다.
#np.full_like(array, fill_value)
var = np.array([2,4,6,8,10])
arr = np.full_like(var, 5) #var array의 크기의 5로 채워진 array 생성
print(arr)

3. 순차적인 값을 가진 배열 생성하기
3.1 arange()
지정된 간격으로 값이 증가하는 1차원 배열을 생성합니다.
#np.arange(start, stop, step, dtype=None)
#start는 시작 값, stop은 종료 값, step은 간격입니다.
arr = np.arange(0,10,3)
print(arr)
3.2 linespace()
지정된 구간에서 균등한 간격으로 나뉜 num개의 값을 포함하는 배열을 생성합니다.
#np.linespace(start, stop, num=50)
arr = np.linespace(0,1,5)
print(arr)출력해보시면, 0부터 1사이의 일정한 간격의 5개의 값을 포함하는 배열을 생성하는 것을 볼 수 있습니다.


4. 랜덤값으로 배열 생성하기
넘파이에서 랜덤값으로 배열을 생성하는 것은 데이터 분석과 머신러닝, 통계학, 컴퓨터 그래픽스 등 여러 분야에서 필수적입니다. 이제 랜덤값으로 배열 생성하는 방법에 대해 소개해드리도록 하겠습니다. 😎
이 부분에 대한 코드웍스 코드는 아래 링크에 있습니다.
4.1 random.rand()
0과 1 사이의 랜덤 실수로 채워진 배열을 생성합니다. 그렇기때문에 코드를 실행시킬 때 마다 다른 배열이 생성됩니다.
#np.random.rand(array_shape)
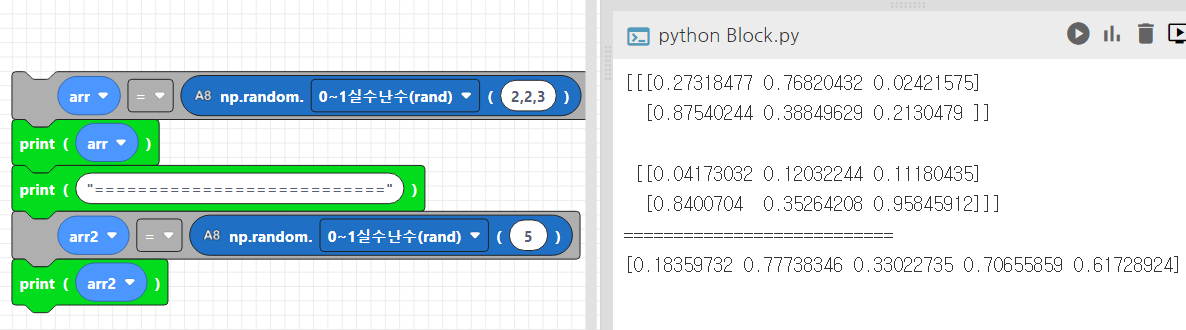
arr = np.random.rand(2,2,3) #2x2x3의 3차원 배열 생성
print(arr)
arr2 = np.random.rand(5) # 길이 5의 1차원 배열 생성
print(arr2)코드웍스에서는 random 관련 함수들을 A8블록에서 제공합니다.

4.2 random.randint()
랜덤 정수 생성 함수로, 특정 범위 내에서 무작위 정수를 생성합니다. 이 함수는 배열의 초기값을 설정하거나, 특정 범위 내에서 샘플링할 때 유용합니다.
#np.random.randint(low, high, size)
arr = np.random.randint(1,10,size=(2,3)) #1이상 10미만의 정수로 구성된 2x3배열
print(arr)
arr2 = np.random.randint(1, 5,(3,2,3)) #1이상 5미만의 정수로 구성된 3x2x3배열
print(arr2)

4.3 random.shuffle()
기존 배열의 순서를 무작위로 섞는 기능을 제공하는 함수로, 데이터를 랜덤하게 셔플해야 할 때 유용합니다. 중요한 점은 np.random.shuffle()이 배열을 제자리에서 직접 섞기 때문에 원본 배열이 변경된다는 것입니다. 이 함수는 주로 데이터셋을 섞어 학습과 테스트 데이터로 나누는 작업 등에서 활용됩니다.
- 제자리 연산: 배열을 직접 섞기 때문에, 원본 배열이 변경됩니다.
- 다차원 배열: 2차원 이상의 배열에서 각 행을 독립적으로 섞습니다. 열 전체가 섞이는 것은 아니므로, 각 행의 순서만 변경된다는 점을 알아두면 좋습니다.
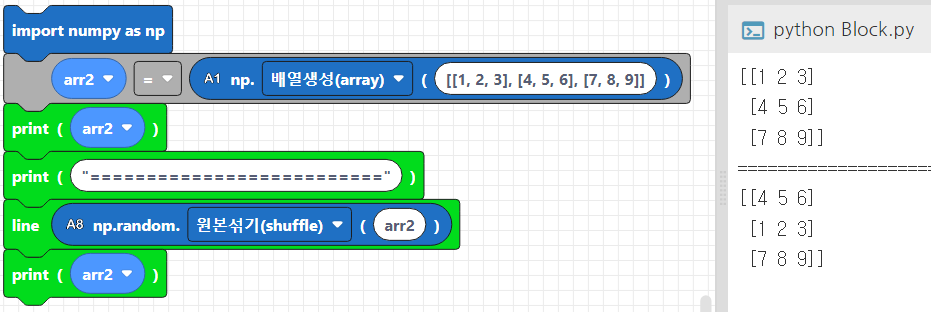
# 배열 생성
arr = np.array([1, 2, 3, 4, 5])
np.random.shuffle(arr)
print(arr)
arr2 = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
np.random.shuffle(arr2)
print(arr2)1차원 배열에서는 순서가 바뀌는 것을 확인하실 수 있습니다.


N차원 배열에서는 각 행의 순서만 변경되는 것을 확인하실 수 있습니다.

무작위 요소가 포함된 코드에서 매번 다른 값이 생성된다면 결과가 매 실행마다 달라질 수 있고, 이는 특히 데이터 분석이나 모델 학습에서 재현성을 떨어뜨리게 되는 문제로 이어집니다. 이를 해결하기 위해 np.random.seed() 함수가 사용됩니다.
4.4 random.seed()
np.random.seed()는 특정 값을 설정하여 난수 생성기의 시작점을 고정시키는 기능을 합니다. 이렇게 하면 같은 코드를 반복 실행해도 매번 동일한 난수 값을 생성하게 되어, 일관된 결과를 보장할 수 있습니다.
따라서, 코드 실행 시 난수로 인한 변동을 줄이고 결과를 검증하거나 다른 환경에서도 동일한 결과를 얻고자 할 때 np.random.seed()를 사용하여 재현성을 높일 수 있습니다.
# 시드 설정
np.random.seed(42)
# 동일한 시드가 설정된 경우, 매번 동일한 난수 배열 생성
arr = np.random.rand(3)
print(arr)한번 이 코드를 여러번 실행시켜 보겠습니다. 그리고 시드를 비활성화 시킨 후 실행을 여러번 해보겠습니다.
seed가 설정되어있을때는 같은 난수가 생성된 것을 확인하실 수 있고, seed가 없을땐, 난수가 실행할때마다 바뀌는것을 알 수 있습니다.😎

지금까지 데이터 분석과 인공지능에서 많이 사용되는 NumPy의 배열 생성 방법에 대해 알아보았습니다. 다양한 방식으로 배열을 생성하고 이를 활용하는 방법을 이해하는 것은 데이터 분석과 인공지능 모델을 구축하는 데 중요한 기초가 됩니다.
앞으로 데이터 분석이나 인공지능 모델을 만드는 과정에서 NumPy 배열의 생성은 핵심적인 역할을 하므로, 잘 기억해두시면 많은 도움이 될 것입니다.
질문있으시면 댓글로 남겨주시면 친절히 답변해드리겠습니다.🤗
본 포스팅이 유용하셨다면 좋아요와 구독 부탁드립니다.🫠

references
[1]https://jalammar.github.io/visual-numpy/
A Visual Intro to NumPy and Data Representation
Discussions: Hacker News (366 points, 21 comments), Reddit r/MachineLearning (256 points, 18 comments) Translations: Chinese 1, Chinese 2, Japanese, Korean The NumPy package is the workhorse of data analysis, machine learning, and scientific computing in t
jalammar.github.io
[2] https://www.nomidl.com/python/numpy-for-data-science-part-1/
[3] https://www.geeksforgeeks.org/python-lists-vs-numpy-arrays/