
안녕하세요 코드웍스(codewalks)입니다.
이번시간에는 파이썬의 기본 자료형중 set(집합)에 대해 알아보겠습니다. 😎
set이란?
파이썬(Python)에서 set은 수학에서의 집합 개념을 프로그래밍으로 구현한 자료구조입니다.
파이썬의 set은 데이터의 중복을 허용하지 않으며, 순서가 없는 데이터 타입입니다. 이 특징 덕분에 set은 중복을 제거하거나, 집합 연산(합집합, 교집합 등)을 처리할 때 유용하게 사용됩니다.
set의 특징
- 중복을 허용하지 않음: 동일한 값이 여러 번 추가되어도 하나만 저장됩니다.
- 순서 없음: 순서를 보장하지 않기 때문에 인덱스나 슬라이싱을 사용할 수 없습니다.
- 수정 가능(Mutable): set에 값을 추가하거나 제거하는 것이 가능합니다.
- 해시 가능한 객체만 저장 가능: set은 해시 가능한 객체만을 저장할 수 있습니다. 예를 들어, 숫자, 문자열, 튜플은 저장 가능하지만, 리스트나 딕셔너리 같은 객체는 저장할 수 없습니다.
1. set 생성하기
set을 생성하는 방법에는 크게 두가지 방법이 있습니다. 중괄호를 활용하는 방법과 set() 함수를 통해 생성하는 방법입니다. 이제 알아보도록 하겠습니다. 🤔
1.1 중괄호 {}
set을 생성하는 가장 간단한 방법은 중괄호를 사용하는 것입니다. 딕셔너리랑 비슷하지만, set은 키와 값이 없다는 차이가 있습니다.
asepa = {'카리나', '윈터', '닝닝', '지젤'}
age = {24,23,22,24}
print(asepa)
print(age)
출력된 결과를 보시면, age set에서는 24가 삭제되어 출력된 것을 확인하실 수 있습니다. 이처럼 파이썬에서 set은 중복을 제거합니다.
1.2 set() 함수
파이썬에서는 내장함수로 set()함수를 제공합니다.
set(iterable)- iterable: 리스트, 튜플, 문자열 등 반복 가능한 객체를 입력으로 받습니다.
- set() 함수는 입력된 객체를 집합 자료형으로 변환하여 반환합니다.
- 만약 중복된 값이 있으면 하나로 합쳐지고, 순서는 보장되지 않습니다.
asepa = set(['카리나', '윈터', '닝닝', '지젤'])
print(asepa)
age = set([24,23,22,24])
print(age)
asepa_string = set('asepa whiplash')
print(asepa_string)

2. set 주요 메서드
파이썬에서는 set과 관련된 메서드들을 제공하여 집합을 효과적으로 다룰 수 있도록 합니다. 이제 주요 메서드들에 대해 알아보겠습니다.
2.1 add() & update()
set 에서 요소를 추가하는 메서드에는 add()와 update()가 있습니다. add()는 하나의 요소만을 추가할때, update()는 하나이상의 요소를 추가할때 사용하게 됩니다.
2.1.1 add()
add() 메서드는 집합에 한가지의 새로운 요소를 추가하는 메서드입니다. 만약 이미 존재하는 값이라면 추가되지 않습니다.
asepa = {'카리나', '윈터', '닝닝', '지젤'}
asepa.add('나비스')
print(asepa)
asepa.add('카리나')
print(asepa)나비스는 기존 asepa set에 존재하지 않기때문에, 잘 추가된 것을 확인하실 수 있었지만, '카리나'는 존재했기때문에 추가되지않는 것을 확인하실 수 있습니다.

2.1.2 update()
update()메서드는 여러 개의 값을 한 번에 추가하도록 합니다.. update() 메서드는 하나 이상의 반복 가능한(iterable) 객체(예: 리스트, 튜플, 문자열 등)를 받아서, 각 요소를 집합에 추가합니다. 이 메서드는 기존에 존재하는 값은 추가하지 않으며, 중복을 자동으로 제거합니다.
asepa = {'카리나', '윈터', '닝닝', '지젤'}
asepa.update(['나비스', '광야', '카리나'])
print(asepa)업데이트할 요소들을 리스트로 제공해서 asepa set에 추가하는 예시입니다. 이때, 중복되는 '카리나' 요소는 중복이기때문에 추가되지 않는것을 확인하실 수 있습니다.

2.2 remove() & discard()
파이썬의 set 자료형에서 요소를 제거하는 방법에는 remove()와 discard() 메서드가 있습니다. 두 메서드는 모두 집합에서 특정 요소를 제거할 때 사용되지만, 존재하지 않는 요소를 제거하려고 할 때의 동작이 다릅니다.
2.2.1 remove()
remove() 메서드는 지정된 요소를 집합에서 제거합니다.
만약 제거하려는 값이 집합에 없다면, KeyError 예외가 발생합니다.
asepa = {'카리나', '윈터', '닝닝', '지젤','나비스'}
asepa.remove('나비스')
print(asepa)
2.2.2 discard()
discard() 메서드는 지정된 요소를 집합에서 제거합니다. 그러나 만약 제거하려는 값이 집합에 없다면, 오류가 발생하지 않습니다. 즉, 존재하지 않는 요소를 제거하려고 해도 안전하게 넘어갈 수 있습니다.
asepa = {'카리나', '윈터', '닝닝', '지젤','나비스'}
asepa.discard('나비스')
print(asepa)2.3 clear()
모든 요소를 제거하여 빈 집합으로 만드는 메서드입니다. 이 메서드는 집합 내의 모든 요소를 삭제하므로, 이후에는 빈 집합만 남게 됩니다.
asepa = {'카리나', '윈터', '닝닝', '지젤','나비스'}
asepa.clear()
print(asepa)모든 요소가 다 삭제되어 빈 집합만 남은 것을 확인하실 수 있습니다.

1, 2 챕터의 코드웍스 코드는 아래 링크에 있습니다.
3. set 연산

파이썬의 집합(set) 자료형은 수학에서 사용하는 집합 연산(합집합, 교집합, 차집합, 대칭차집합)을 지원합니다. 이러한 연산을 사용하면 두 집합 간의 관계를 쉽게 처리할 수 있으며, 이를 통해 다양한 문제를 효율적으로 해결할 수 있습니다.
a = {1,2,3}
b = {3, 4, 5}
print("합집합", a.union(b)) #합집합 연산
print("교집합", a.intersection(b)) # 교집합 연산
print("차집합", a.difference(b)) # 차집합 연산
print("대칭 차집합", a.symmetric_difference(b)) #대칭차집합 연산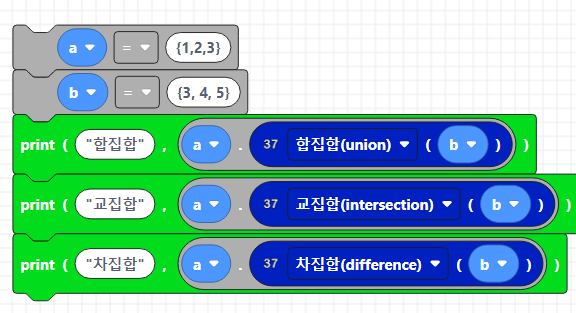

4. set의 활용 예시
본 예시에서 사용한 코드는 아래 링크에서 제공합니다.
4.1 중복 제거
set은 중복을 자동으로 제거하는 특성을 가지고 있기 때문에, 리스트나 다른 반복 가능한 객체에서 중복된 값을 제거할 때 매우 유용합니다. 🤔
ex = [5, 6, 1, 2, 2, 3, 4, 4, 5, 1]
ex_set = set(ex)
print(ex_set)
var = list(ex_set)
print(var)예시로 제공된 리스트에 중복된 요소들이 많은 것을 확인할 수 있는데, 이를 set으로 만들어 출력해보면, 중복되는 요소는 제거되어서 출력되는 것을 확인하실 수 있습니다. 이를 리스트로 변환하여 출력하시면 ex 리스트에서 중복을 제거한 리스트 결과가 나오게 됩니다.

4.2 특정 요소 포함 여부 확인하기
set 자료형은 특정 요소가 집합에 포함되어 있는지 빠르게 확인할 수 있는 장점이 있습니다. 이 과정은 해시 방식으로 이루어져서 리스트나 튜플에 비해 탐색 속도가 훨씬 빠릅니다.
ex = {1, 2, 3, 4, 5, 6}
print(0 in ex)
print(6 in ex)
print(8 in ex)
4.3 데이터 필터링
set의 집합 연산(합집합, 교집합, 차집합 등)을 활용하면, 특정 조건에 맞는 데이터를 필터링하는 작업이 매우 간단해집니다.
4.3.1 두 리스트에서 공통된 값 추출하기
두 리스트에서 공통된 값을 추출하는 작업은 set의 교집합 연산을 사용하여 쉽게 해결할 수 있습니다. Python의 set 자료형은 기본적으로 집합 연산을 제공하며, 이를 통해 두 리스트에서 공통된 요소를 찾을 수 있습니다.
# 두 리스트 정의
list1 = [1, 2, 3, 4, 5]
list2 = [4, 5, 6, 7, 8]
# 집합으로 변환 후 교집합 구하기
common = set(list1) & set(list2)
print(common)
4.3.2 특정 기준에 맞는 데이터 필터링
특정 기준에 맞는 데이터를 필터링할 때도 set의 차집합이나 합집합 연산을 사용할 수 있습니다. 예를 들어, 특정 조건을 만족하는 값만 걸러내거나, 특정 기준에 맞지 않는 데이터를 제외하는 작업을 할 수 있습니다.
짝수이면서 5보다 큰 숫자들을 필터링해서 출력해보도록 하겠습니다.
data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
even = {i for i in data if (i % 2) == 0}
greater_five = {i for i in data if i>5}
ex = even & greater_five
print(ex)1부터 10까지의 숫자중에 5보다 크면서 짝수인 숫자들이 필터링되어서 잘 출력되는 것을 확인하실 수 있습니다.

5. Set 메서드 요약
| 메서드 | 설명 |
| add(element) | 요소 추가 |
| remove(element) | 요소 제거(존재 x 오류 o) |
| discard(element) | 요소 제거(존재 x, 오류 x) |
| clear() | 모든 요소 제거 |
| union(set) | 합집합 반환 |
| intersection(set) | 교집합 반환 |
| difference(set) | 차집합 반환 |
| symmetric_differnece(set) | 대칭 차집합 반환 |
지금까지 파이썬의 기본적인 자료형인 set 집합 자료형에 대해 알아보았습니다. set 자료형은 데이터에서 중복을 제거하고, 특정 조건에 따라 데이터를 필터링할 때 유용하게 사용 할 수 있습니다.
궁금하신 점은 댓글로 남겨주시면 친절히 답변해드리겠습니다.
긴글 읽어주셔서 감사합니다 😊

'🦎파이썬 > 🧱 파이썬 기초 블록코딩' 카테고리의 다른 글
| [파이썬 기초] 딕셔너리 dictionary (9) | 2024.10.26 |
|---|---|
| [파이썬 기초] 리스트 List (5) | 2024.10.16 |
| [파이썬 기초] 반복문 for (5) | 2024.10.12 |
| [파이썬 기초] 자료형과 연산 - 숫자형, 부울형, 문자열 (8) | 2024.10.06 |
| [파이썬 기초] 조건문 if (11) | 2024.09.22 |
| [파이썬 기초] 출력 print (2) | 2024.09.12 |