
안녕하세요 코드웍스입니다!
이번 시간에는 데이터 분석에서 많이 쓰이는 pandas의 dataframe(데이터프레임)을 코드웍스를 활용하여 배워보도록 하겠습니다.
목차
pandas란?
판다스(pandas)는 파이썬에서 사용하는 데이터분석 라이브러리 입니다.
데이터분석, 조작, 시각화 등 다양한 기능을 제공합니다.
pandas는 크게 두가지 데이터 구조를 제공하는데, series와 dataframe입니다.
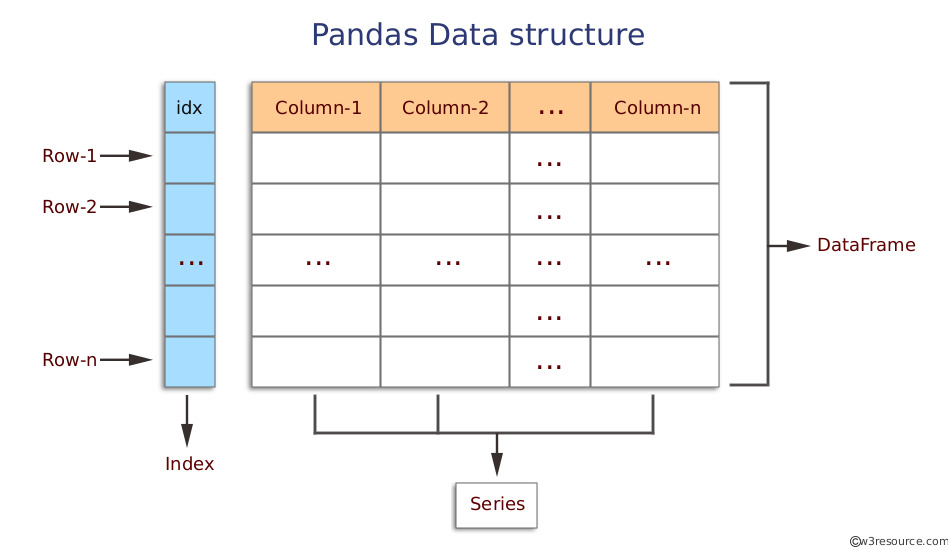
- series: 1차원 데이터 구조
- dataframe: 2차원 데이터 구조, 행과 열로 구성된 표 형태의 데이터

이번 시간에는 판다스의 데이터프레임(dataframe)에 대해서 자세히 알아보도록 하겠습니다.
1. pandas 데이터프레임(dataframe) 기본 생성
1.1 pandas import
그럼 pandas를 사용하기 위해 import 하겠습니다.
C블록의 데이터분석(pandas)를 클릭후, 제일 위에 있는 import pandas를 클릭합니다.
1.2 dataframe 생성
pandas 라이브러리를 import 했으면, dataframe을 생성 할 수 있게 됩니다. 이제 두번째 블록을 클릭합니다.
import한 pandas 블록과 연결 후, csv파일읽기를 클릭하면, 여러가지 형태의 데이터를 가지고 올 수 있는 pandas의 기능들이 나타납니다.
이번 포스트에선 데이터프레임을 생성해보도록 하겠습니다.
데이터프레임 생성을 클릭하면, 아래와 같이 기본적인 데이터프레임이 생성됩니다.

데이터 프레임을 생성할때는 다양한 형태의 데이터를 입력할 수 있는데, 대표적으로 list형태와 dictionary형태를 입력할 수 있습니다.
텍스트 파이썬 코드는 아래와 같이 나타낼 수 있습니다.
import pandas as pd
df = pd.DataFrame()
여기서 잠깐
데이터프레임을 출력하려면 어떻게 해야할까요? 🤔
2. 데이터프레임 출력하기
생성된 데이터프레임을 확인하기 위해선 출력을 해봐야하는데요, 다양한 방법을 알아보도록 하겠습니다.

다시 C데이터 분석 탭에 들어가서 print블록을 클릭합니다.

아래 화살표를 누르면 다양한 선택지가 있습니다. 그 중, 우리는 상위, 하위, 전체 출력 하는것만 이번 포스트에서 다루도록 하겠습니다.
2.1 상위 행 출력
아래는 상위행 출력의 예시입니다.
df.head() #상위 5개 출력
df.head(N) #상위 N개 출력
df.head()는 출력하고자 하는 데이터프레임의 상위 5개를 출력하게 됩니다.
df.head(N)은 상위 N개의 데이터를 출력하라는 뜻입니다.
아래 예시에서는 상위 3개의 데이터를 출력하도록 하였습니다.

2.2 하위 행 출력
아래는 하위행 출력의 예시입니다.
df.tail()는 출력하고자 하는 데이터프레임의 하위 5개를 출력하게 됩니다.
df. tail (N)은 하위 N개의 데이터를 출력하라는 뜻입니다.
아래 예시에서는 위 3개의 데이터를 출력하도록 하였습니다.
df.tail()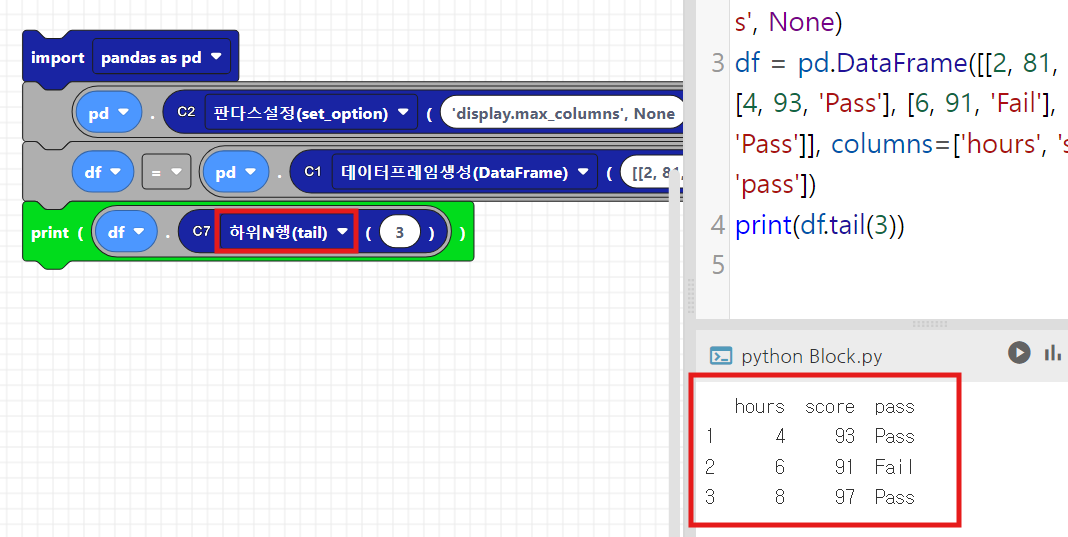
2.3 전체 출력
아래는 전체 데이터프레임의 출력 예시입니다.
print(df)먼저 데이터프레임 df를 오른쪽 마우스 클릭 후, 제일 위에 나오는 복제를 클릭합니다.
그 후, print블록에 가져다 놓고 실행을 누르면 데이터프레임 전체가 출력된 것을 확인하실 수 있습니다.


데이터프레임을 출력하는 방법도 알았으니, 이제 리스트와 딕셔너리로 데이터 프레임을 어떻게 생성하는지 알아보도록 하겠습니다.
3. pandas dataframe 자료형별 생성 방법
3.1 List를 활용한 데이터 프레임 생성
리스트를 생성하기 위해 '0번 변수'를 클릭후, '변수 만들기'를 클릭합니다.

그 다음 새 변수 이름에 리스트의 우리가 사용할 리스트의 변수명을 넣어주는데, 우리는 name_list, country_list라고 만들겠습니다.
name_list 라고 입력 후, 확인을 누르면 아래와 같이 변수가 생성된 것을 확인 할 수 있습니다.
이제, 가장 첫번째 블록을 클릭해서 가져다 놓습니다.
country_list도 동일하게 만들어줍니다.

우리는 블랙핑크 멤버들의 이름과 국적을 나타내는 데이터프레임을 만들어보도록 하겠습니다.
아래 코드와 같이 name_list에는 블랙핑크 멤버의 이름, country_list에는 블랙핑크 멤버의 출신 국가를 리스트로 만들어봅시다.
name_list = ['제니', '리사', '지수','로제']
country_list =['한국', '태국', '한국','뉴질랜드']

리스트 생성 후, C 데이터분석을 클릭 후, 두번째 블록을 클릭합니다. list에 끌어다 놓은 후, 데이터프레임생성(DataFrame)을 클릭합니다. 그 후 자동으로 생성된 내용을 지웁니다.


3.1.1 list로 단순 dataframe 생성
그 후, 데이터프레임 생성 안 빨간색 박스에 아래와 같이 [name_list, country_list]를 입력합니다.
df = pd.DataFrame([name_list, country_list])
그럼 위와같이 두번째 빨간색 박스와 같이 데이터 프레임이 생성된 것을 알 수 있습니다.
3.1.2 list로 index지정 후 dataframe 생성
이때 각 열의 데이터 이름을 넣고 싶다면, index로 지정해줄 수 있습니다.
df = pd.DataFrame([name_list, country_list], index=['name','country'])
index를 지정해주면, 위와 같이 각 열의 데이터 이름을 지정할 수 있습니다.
3.1.3 colum을 list로 지정 후 list로 dataframe 생성
만약 블랙핑크 멤버들의 이름을 column이름으로 지정하고싶다면, 아래와 같이 columns에 name_list를 넣으면 됩니다.
df = pd.DataFrame(data=[country_list], columns=name_list, index=['country'])
3.1.4 다중 list로 dataframe 생성
다중 list로 간편하게 dataframe을 생성하는 방법도 있습니다. 아래와 같이 멤버와 출신 국가를 하나의 리스트로 묶어서 이중리스트를 생성합니다.
data = [['제니', '한국'], ['리사','태국'], ['지수','한국'],['로제','뉴질랜드']]
그 후, pandas dataframe 생성에서 data를 넣고, column의 이름을 지정해주면 아래와 같이 출력됩니다.
df = pd.DataFrame(data, columns=['name','country'])
이제 딕셔너리로 데이터프레임을 생성해보도록 하겠습니다.
3.2 Dictionary를 활용한 데이터프레임 생성
dictionary를 선언하는 각 방법을 통해 데이터프레임을 생성하는 방법을 알아보도록 하겠습니다. 이번 예시에서도 블랙핑크 멤버들의 이름과 출신 국가를 담는 데이터프레임을 만들도록 하겠습니다.
3.2.1 dictionary 생성하기
{} 괄호를 통하여 딕셔너리를 선언합니다. dictionary 기본 구조인 {'key': value} 로 선언해줍시다.
data = {'name':['제니', '리사', '지수','로제'], 'country':['한국', '태국', '한국','뉴질랜드']}
df = pd.DataFrame(data)그 후, dataframe생성 클릭 후, dictionary를 넣고 출력을 해보면, 잘 생성된 것을 볼 수 있습니다.
리스트와는 다르게 colum이름을 따로 지정을 안해주더라도, dictionary의 key값이 자동으로 colum명으로 지정되는 것을 확인 할 수 있습니다.

3.2.2 dict() 생성자를 통하여 생성하기
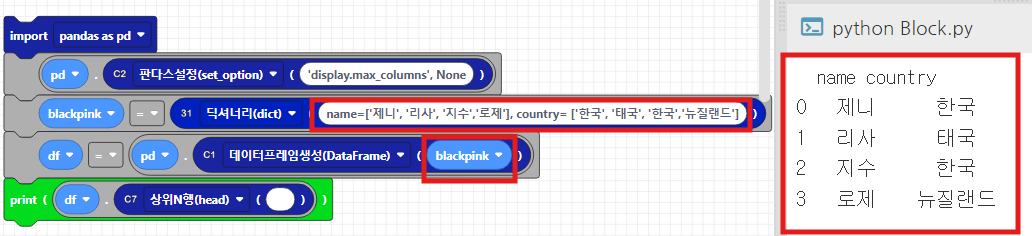
일단 blackpink라는 변수를 생성해주고, 3번 내장함수안에 있는 첫번째 31번 블록을 클릭합니다.

그 후, 딕셔너리(dict)를 클릭합니다. var부분은 지워줍니다.

그 후, dict 뒷 부분에 요소들을 넣어줍니다. 이번엔 key = value 형식으로 넣어줍니다.
blackpink = dict(name=['제니', '리사', '지수','로제'], country= ['한국', '태국', '한국','뉴질랜드'])
df = pd.DataFrame(blackpink)그 후 dataframe 생성을 위에서와 같이 가져온 후, 빈칸에 blackpink를 넣고 출력해보면, 잘 생성된 것을 확인하실 수 있습니다.
지금까지 코드웍스(codewalks)를 활용하여 블록으로 dataframe을 생성하는 방법을 알아보았습니다.
다음 시간에는 코드웍스를 활용하여 pandas로 csv파일을 dataframe으로 받아오는 방법을 포스팅하도록 하겠습니다.
감사합니다 :)
코드웍스 데이터분석 강의도 참고하세요!
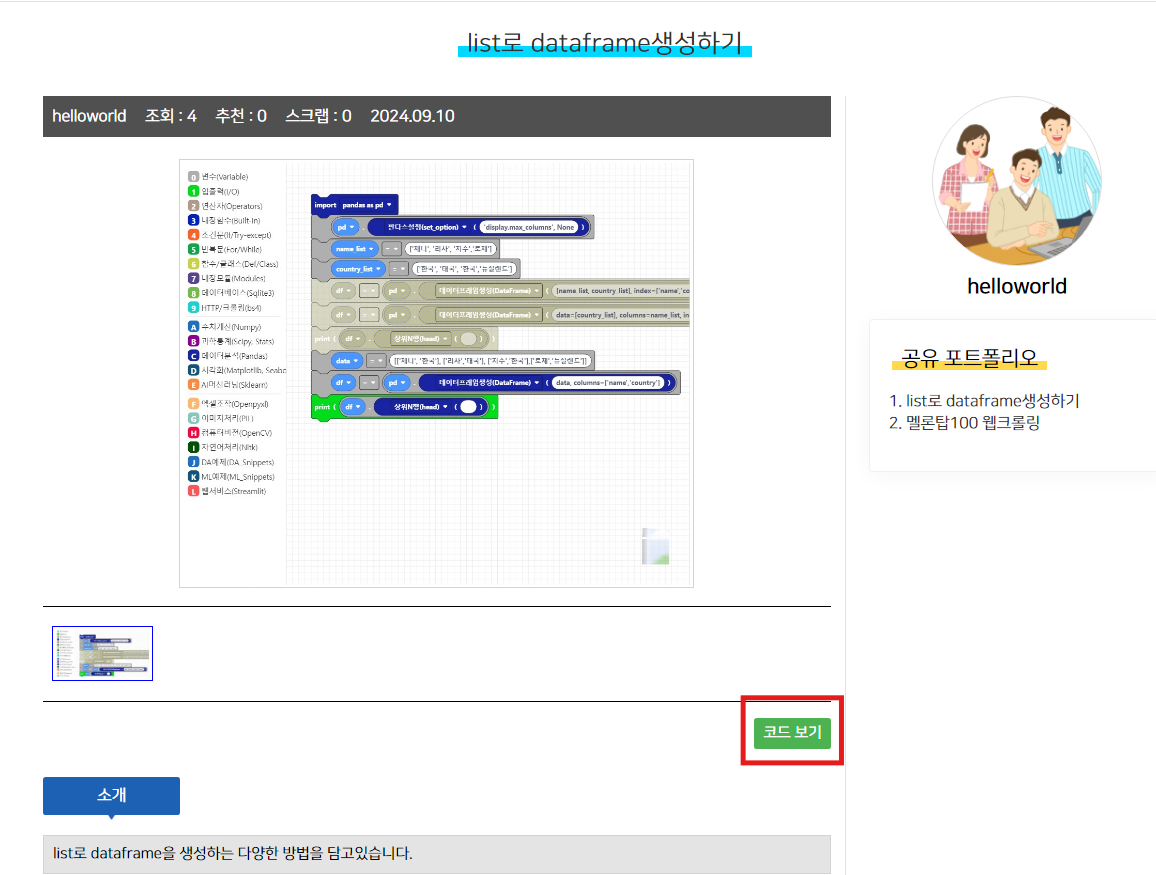
본 포스트에 사용된 블록 코드는 아래 링크에서 사용할 수 있습니다.
링크에 대한 사용방법은 아래 접은글에 있습니다.
링크 사용법
아래 초록색 코드보기를 클릭하시면 제공된 코드를 사용하실 수 있습니다.
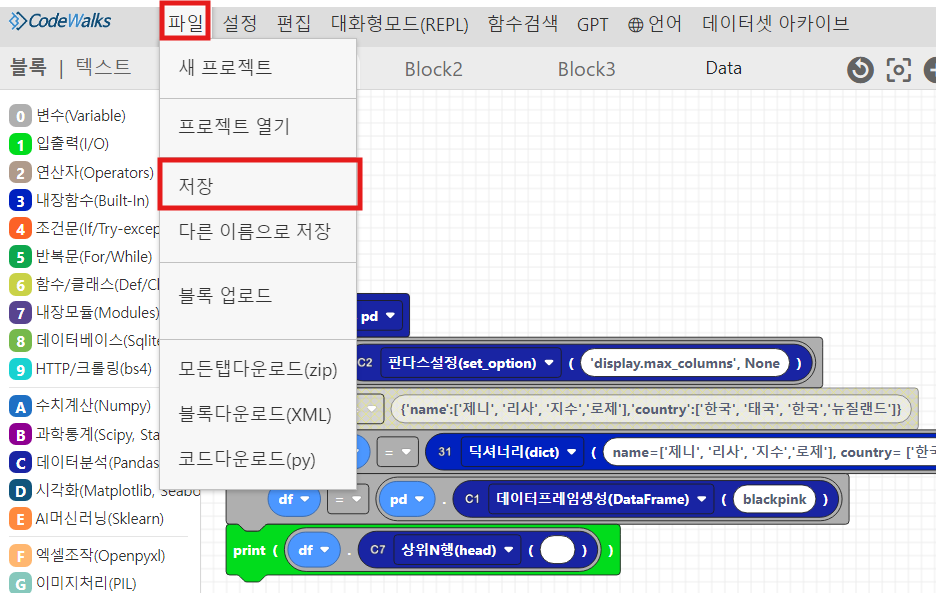
본인이 실제 학습한 코드를 저장하고싶다면, 파일> 저장 > 예 클릭하시면,
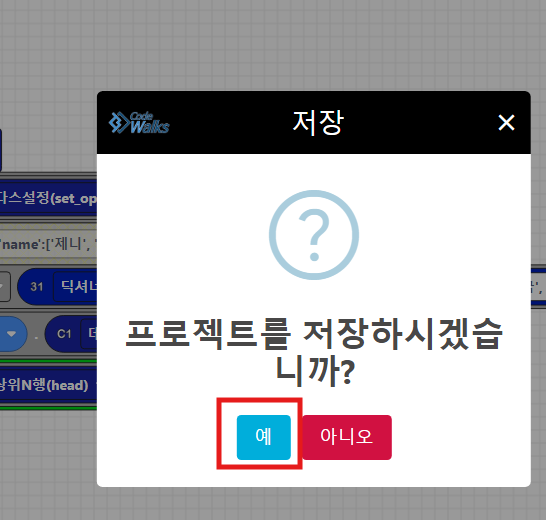
프로젝트 제목, 설명 분야를 설정하여 저장하실 수 있습니다.
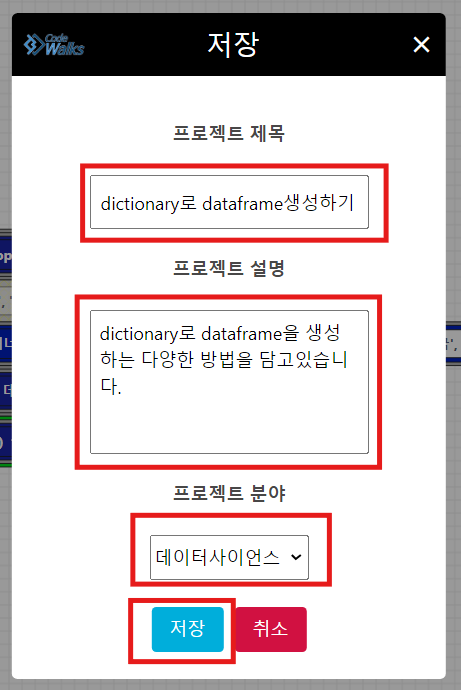
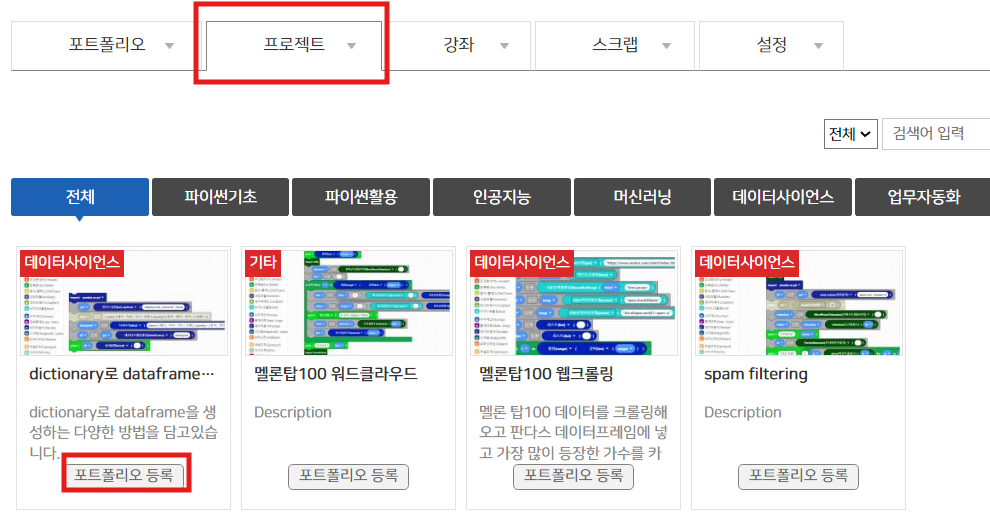
저장된 프로젝트는 마이페이지 > 프로젝트 에서 보실 수 있습니다.

포트폴리오를 등록하고 싶으시다면, 마이페이지> 프로젝트> 포트폴리오 등록을 클릭하시면 다른 사람들에게 내 코드를 공유할 수 있습니다

'📊 데이터 분석 > 🐼 판다스 pandas' 카테고리의 다른 글
| [판다스 기초] DataFrame 정보 확인 방법 총정리 (5) | 2024.10.28 |
|---|---|
| [판다스 기초] 데이터프레임(dataframe) csv 파일 읽기 & 쓰기 (10) | 2024.10.01 |