

안녕하세요 코드웍스입니다!
이번 시간에는 코드웍스를 활용해서 판다스(pandas) 데이터프레임(dataframe)으로 csv파일을 읽어오고, 저장하는 방법을 알아보도록 하겠습니다.

1. csv 파일이란?
- Comma Seperated Value(csv)의 줄임말입니다.
- 매우 단순한 텍스트 파일 형식으로, 데이터가 쉼표로 구분된 값들로 저장됩니다.
- 데이터가 단순 텍스트로 저장되기 때문에 파일 크기가 매우 작고, 읽고 쓰는 속도가 빠릅니다.
이제 판다스로 csv파일을 읽어오고 쓰는 방법을 소개해드리도록 하겠습니다.
그전에, 판다스 데이터프레임의 행(row), 열(column), 인덱스(index)가 무엇을 의미하는지 설명하는 그림을 참고하시길 바랍니다.
2. csv파일 읽기(read)
판다스에서는 csv파일을 쉽게 읽어와서 데이터를 DataFrame 형태로 변환해 주는 read_csv함수를 제공합니다.
코드웍스에서는 C 데이터분석 블록> 2번째 블록에서 이 기능을 제공합니다.
먼저 판다스를 import 한 후, read_csv블록을 끌어다 놓습니다.
코드웍스에서 기본적으로 제공하는 exam.csv파일을 읽어온 후 출력해보겠습니다.
exam.csv파일의 원본은 아래 사진의 폴더모양을 클릭하면 기본적으로 제공되는 파일들이 나오게된는데, exam.csv파일을 더블클릭하면, Data탭에서 원본파일을 볼 수 있습니다.
이제 블록을 실행해보면, 아래와 같이 깔끔하게 출력되는 것을 확인하실 수 있습니다.
(데이터프레임 출력하는 내용은 이전 포스트에서 자세히 확인하실 수 있습니다. [판다스 기초] 데이터프레임(dataframe)-생성&출력)
텍스트 파이썬 코드로 작성하면 아래와 같습니다. 텍스트로 작성할때는, 파일 위치를 잘 지정해주셔야 오류없이 출력됩니다. 파일위치는 윈도우 기준으로, 파일의 오른쪽을 클릭하면 경로로 복사를 클릭하면, 파일의 경로가 복사되어 붙여넣기를 하면 됩니다.
import pandas as pd #판다스 import
df = pd.read_csv('파일위치/파일명.csv') #파일위치와 파일명 정확히 기재
print(df.head()) #데이터프레임의 첫 5줄 출력
이제 기본적인 읽어오기를 알았으니, 많이 쓰이는 옵션들에 대해 알아보도록 하겠습니다.
2.1 header - 어느 행(row)을 열(column) 이름으로 사용할지 지정 옵션
header는 기존의 행중에 어느 행을 열 이름으로 지정해주는지 결정하는 옵션입니다.
read_csv에서 header의 여러 옵션에 따라서 읽어보고, 출력해보도록 하겠습니다. 아래는 header 옵션에 따른 설명입니다.
| header 옵션 | 설명 |
| header = 0 (기본값) | 첫 번째 행(0번째 index)을 열 이름으로 사용합니다. |
| header = None | 첫 번째 행을 데이터로 처리하고, 열 이름은 숫자로 자동 지정됩니다. |
| header = n | n번째 행을 열 이름으로 사용하고, 그 이전 행들은 무시하거나 데이터로 처리합니다. |
| header = 'infer' | pandas가 첫 번째 행을 자동 분석하여 열 이름으로 설정. |
아래 블록은 read_csv파일을 옵션별로 데이터프레임으로 받아오도록 df,df2,df3로 각각 받아오도록 하였고, 각각의 데이터프레임을 출력하도록 하는 코드웍스 코드입니다. header에 따라서 열의 이름이 각각 지정된 것을 확인하실 수 있습니다.
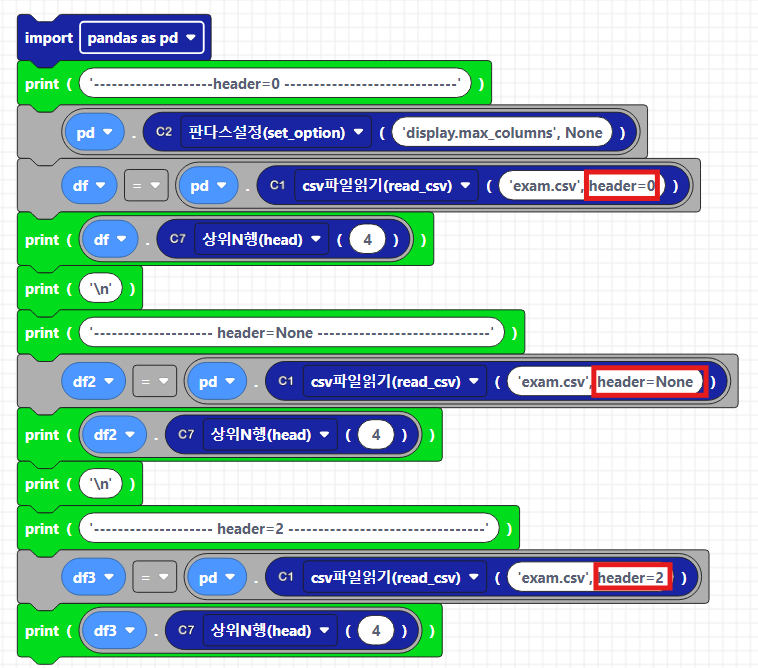
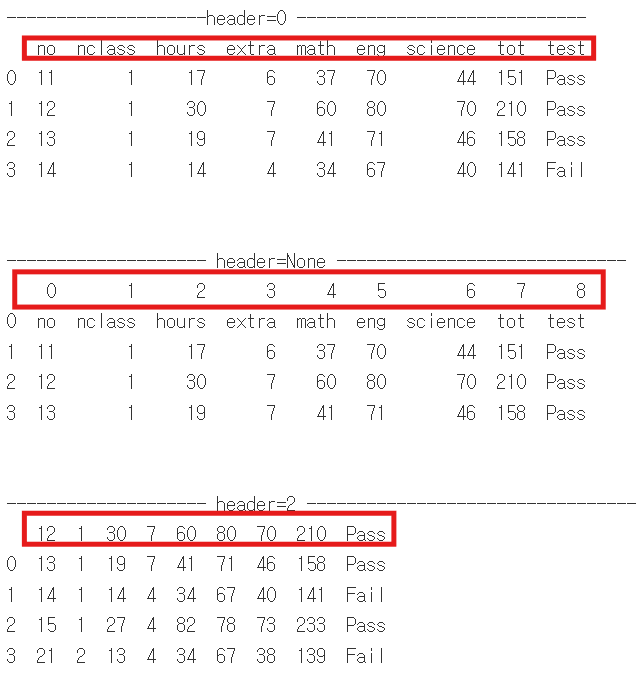
이를 파이썬 텍스트 코드로 작성하면 아래와 같습니다.
df = pd.read_csv('파일명.csv', header= 0)
print(df.head(4))
df2 = pd.read_csv('파일명.csv', header= None)
print(df2.head(4))
df3 = pd.read_csv('파일명.csv', header=2) #3번째 행을 열 이름으로 사용합니다
print(df3.head(4))
2.2 sep - 구분자 지정 옵션
csv파일은 보통 이름과 같이 대부분 쉼표(, 콤마)로 구분되어있지만, 실제로는 쉼표가 아닌 다른 구분자를 사용하는 경우도 많습니다. 이를 위해 판다스에서는 sep으로 받아올 파일의 구분자를 지정하는 기능이 있습니다.
- sep = ',' (기본값)
- sep = '\t' (tab구분)
- sep =';' (세미클론 구분)
- sep =' ' (공백 구분)
우리는 에스파의 멤버이름, 출신국가, 키, 나이 정보 데이터를 이용해서 실습하겠습니다.
2가지 버전의 데이터를 준비했는데요, 세미클론, 공백으로 이루어진 데이터셋을 제가 만들었고, 이를 이용해서 sep를 이용해보도록 하겠습니다. 이용할 파일은 접은글에서 다운로드 하실 수 있습니다.

코드웍스에서는 활용하고싶은 파일을 업로드 할 수 있는데요, 블록 텍스트 부분 옆에 파일 플러스 아이콘을 눌러주시면, 제일 왼쪽의 업로드 버튼을 클릭합니다. 그리고 본인이 원하는 파일을 업로드해서 사용할 수 있습니다. 각 데이터를 더블 클릭하면, 데이터 탭에서 데이터를 확인할 수 있습니다.
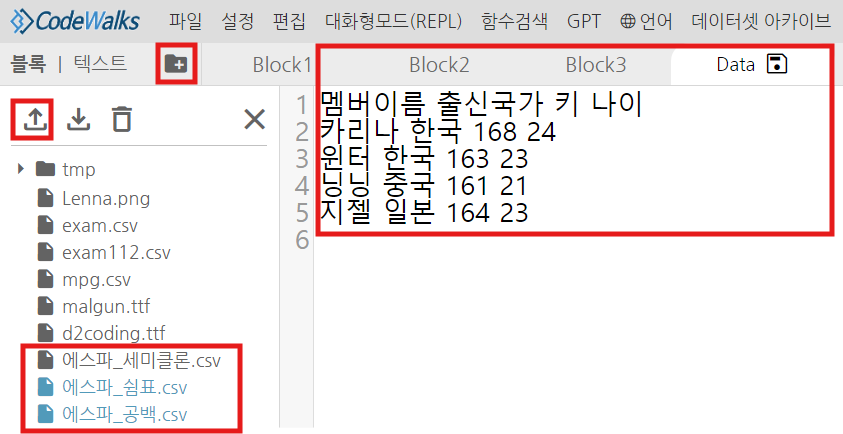
이제 sep 옵션 몇가지로 실습해보도록 하겠습니다.
2.2.1 sep =';' (세미클론 구분)
에스파_세미클론 파일은 세미클론으로 구분되어있는 파일인데요, 이를 sep 기본 옵션으로 놓고 출력, sep=';' 옵션으로 놓고 각각 출력해보자면, 기본옵션일때는 각 column을 하나의 데이터로 읽어들인것을 볼 수 있습니다. sep=';' 옵션일때는 이쁘게 잘 출력되는 것을 확인하실 수 있습니다.
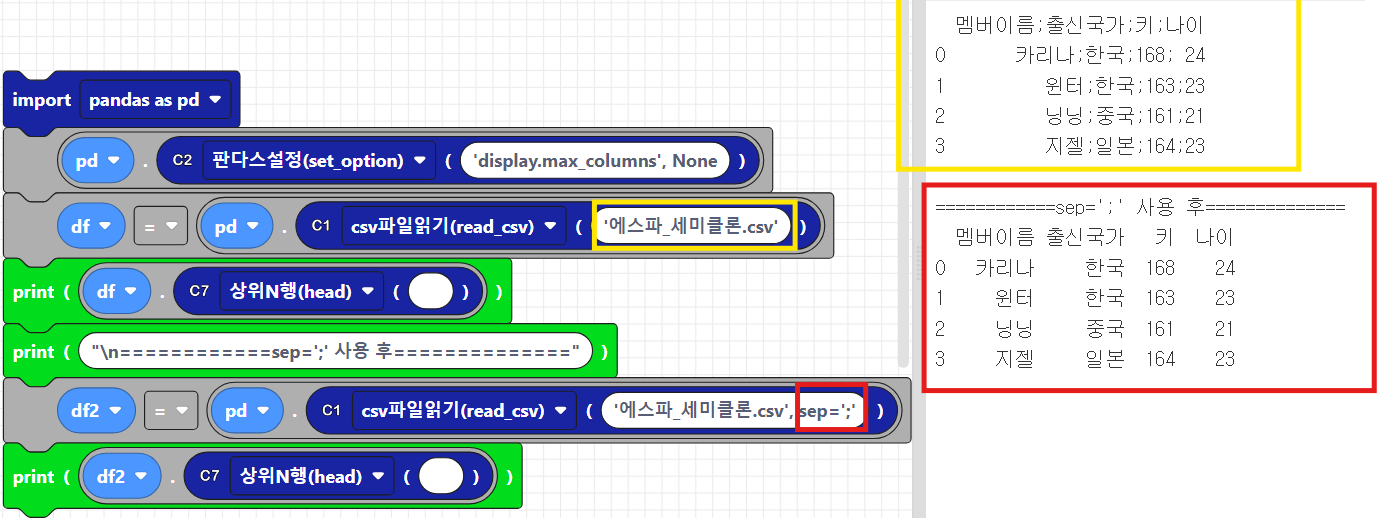
텍스트 파이썬 코드로 작성하면 아래와 같습니다.
df = pd.read_csv('에스파_세미클론.csv') #sep 기본옵션 ,사용
print(df.head())
print("\n============sep=';' 사용 후==============")
df2 = pd.read_csv('에스파_세미클론.csv', sep=';') #sep 사용
print(df2.head())2.2.2 sep =' ' (공백 구분)
위의 실습과 마찬가지로 이번에는 공백으로 이루어진 파일을 받아와서, sep 기본 옵션과 sep=' ' 옵션으로 놓고 각각 출력해보겠습니다. 기본옵션일때는 각 column을 하나의 데이터로 읽어들인것을 볼 수 있습니다. sep=' ' 옵션일때는 이쁘게 잘 출력되는 것을 확인하실 수 있습니다.
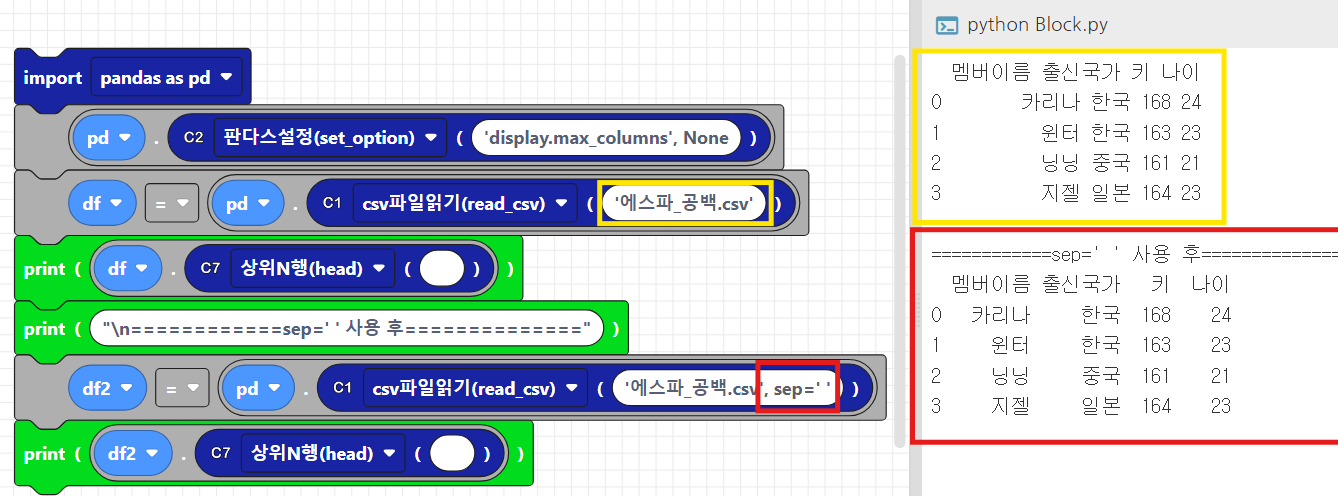
텍스트 파이썬 코드로 작성하면 아래와 같습니다.
df = pd.read_csv('에스파_공백.csv')
print(df.head())
print("\n============sep=' ' 사용 후==============")
df2 = pd.read_csv('에스파_공백.csv', sep=' ')
print(df2.head())2.3 index_col - 열(column)을 인덱스(index)로 지정하는 옵션
- DataFrame의 인덱스로 사용할 열(column)을 지정할 때 사용하는 옵션입니다.
- index_col에 열 번호(또는 열 이름)를 넣으면 해당 열을 인덱스로 설정할 수 있습니다.
- index는 데이터프레임에서 각 행을 고유하게 식별하는 데 사용되며, 데이터를 더 효율적으로 조회하고 조작하는 데 유용합니다.
본 실습에서는 코드웍스에서 기본으로 제공하는 exam.csv 파일을 사용하겠습니다.
아래는 index_col을 각각 열 번호, 열 이름으로 지정해보고 돌려본 결과입니다. 아무설정을 안했을땐, 숫자들이 index로 지정된 것을 확인하실 수 있습니다. index_col을 0으로 지정했을땐, 열 번호가 0번인(첫번째 열)을 index로 지정한 것으로, 'no' 열이 index로 지정된 것을 확인하실 수 있습니다. 마지막으로 열 이름으로 index_col을 지정했을땐, index로 해당 열이 지정된 것을 확인하실 수 있습니다.
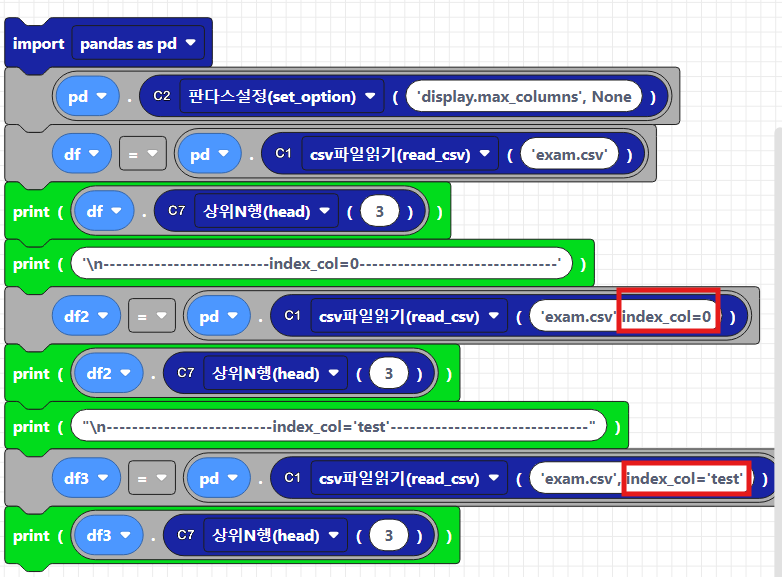
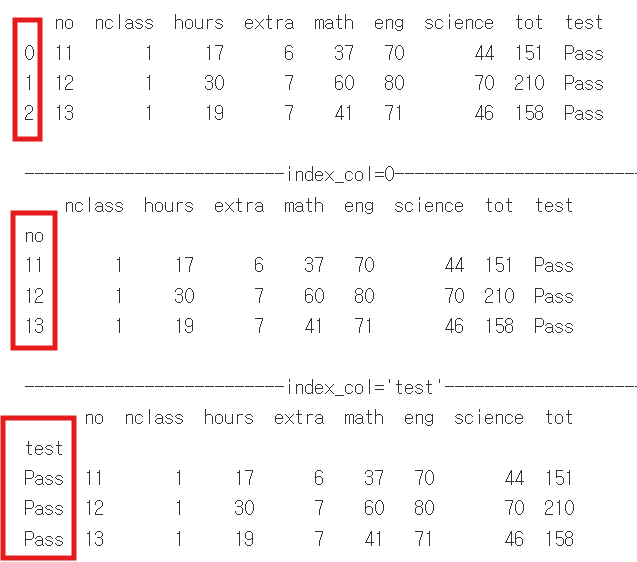
파이썬 텍스트 코드로 나타내면 아래와 같습니다.
df = pd.read_csv('exam.csv') #기본설정
print(df.head(3))
df2 = pd.read_csv('exam.csv',index_col=0) #첫번째 열을 index로 사용
print(df2.head(3))
df3 = pd.read_csv('exam.csv', index_col='test') # 'test'라는 이름의 열을 index로 사용
print(df3.head(3))
2.4 names- 열(column) 이름 수동으로 지정 옵션
- CSV 파일에 열(column) 이름이 없거나, 기존의 이름을 무시하고 새로운 컬럼 이름을 설정하고 싶을 때 사용하는 옵션입니다.
- 리스트 형태로 새로운 컬럼 이름을 제공해야 합니다.
- 이 옵션은 header=0과 같이 사용하는 경우가 많습니다.
본 실습도 위에서와 같이 기본으로 제공되는 exam.csv파일을 사용하겠습니다. 일단 header=0으로 설정해주어야 column이름을 대체할 수 있습니다. 제일 처음예시는 기본으로 제공되는 데이터프레임을 출력한 것이고, 여기에 주어진 column이름을 한국어로 대체하기 위해, 새로운 column이름을 names=[]로 정의하여 지정하면, 아래와같이 수동으로 지정한 column이름이 출력된 것을 확인할 수 있습니다.
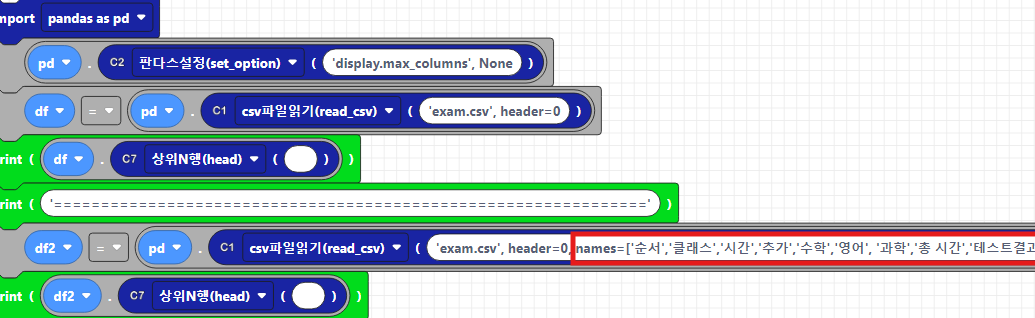
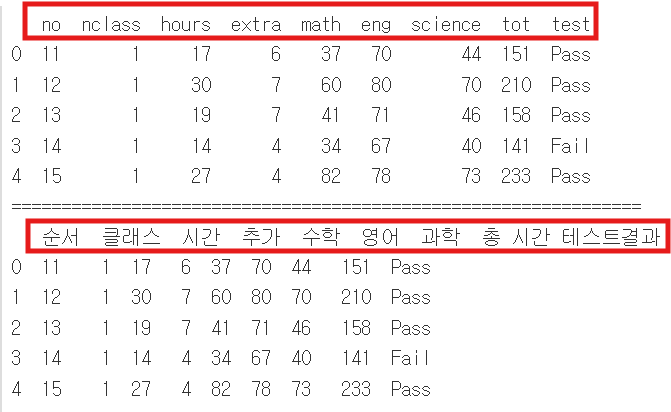
아래는 텍스트 파이썬 코드입니다.
df = pd.read_csv('exam.csv', header=0, names=['순서','클래스','시간','추가','수학','영어', '과학','총 시간','테스트결과'])
print(df.head())3. csv파일 쓰기(write)
이제 csv 파일을 읽어오는 부분을 알아봤으니, 우리가 다룬 데이터들을 csv파일로 내보내는 방법을 알아보겠습니다. pandas에서는 to_csv() 라는 아주 간단한 함수를 제공합니다. 기본적인 사용형태는 아래와 같습니다.
DataFrame.to_csv('폴더/저장할 파일명.csv',index=False, columns=None, header=True, encoding='utf-8-sig')코드웍스에서는 c 데이터분석 블록> 제일 마지막 블록 Ce블록에서 제공합니다.
to_csv에서 제공하는 옵션들은 read_csv와 비슷하기 때문에, 많이 쓰이는 옵션들만 간단히 짚어보고 넘어가겠습니다.
3.1 sep- 구분자 설정 옵션
기본적으로 sep은 쉼표(콤마,)로 설정되어있지만, 본인이 원하는 구분자를 설정할때 사용합니다. read_csv와 비슷하게 사용하면 됩니다.
df = pd.read_csv('exam.csv', header=0)
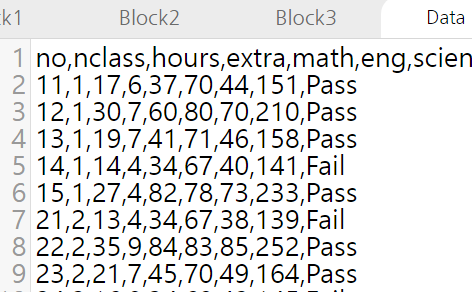
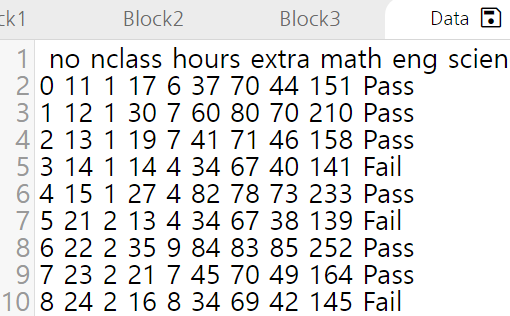
df.to_csv('filename.csv',sep=' ') #df를 filename.csv라는 파일로 공백으로 구분해서 저장
아래는 원본 exam.csv파일(왼쪽)과 to_csv를 사용하여 데이터프레임을 csv로 저장한 파일의 결과물입니다. sep에서 공백으로 설정했듯, 공백으로 구분되어 저장된 것을 확인하실 수 있습니다.
3.2 header- 열 이름 포함 여부 옵션
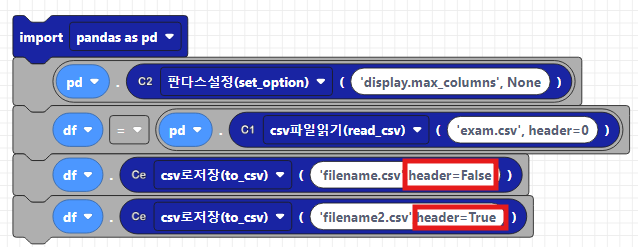
기본값은 True로, 열 이름을 첫 번째 행에 포함합니다. 열 이름을 제외하고 싶다면 header=False로 설정할 수 있습니다. 두 옵션으로 설정하여 csv로 저장해보겠습니다.
df.to_csv('filename.csv',header=False)
df.to_csv('filename2.csv',header=True)저장된 파일은 파일플러스를 클릭하시면 확인하실 수 있습니다.
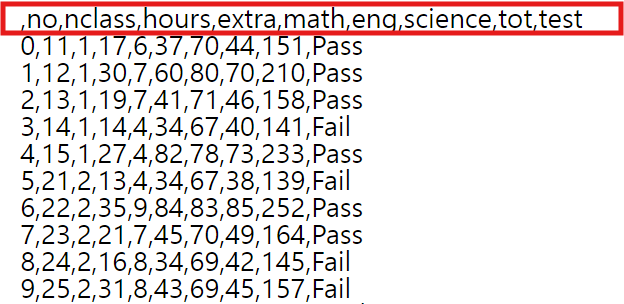
각 파일을 확인해보면, false로 설정했을때는 열 이름이 없는채로 저장된 것을 확인하실 수 있고, true로 설정했을땐, 열 이름이 있는채로 저장된 것을 확인하실 수 있습니다.

3.3 index- 인덱스 포함 여부 옵션
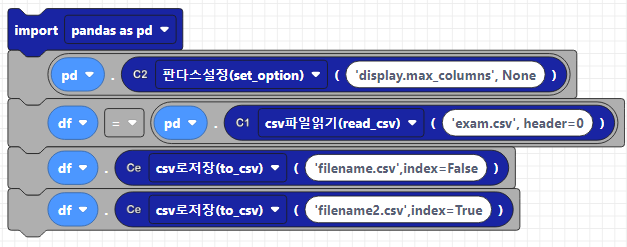
index옵션의 기본값은 True로, dataframe을 csv로 저장할때, 인덱스를 함께 저장합니다. 인덱스를 제외하고 싶으면 index=False로 설정하면 됩니다. 두 옵션을 비교해보겠습니다.
df.to_csv('filename.csv',index=False)
df.to_csv('filename2.csv',index=True)코드웍스 코드는 아래와 같습니다.
아래는 실행 결과입니다. 왼쪽은 false로 설정했을때의 결과로, index가 없이 저장된 것을 확인하실 수 있고, 오른쪽은 true로 설정하여 index가 있는채로 저장된 것을 확인하실 수 있습니다.


3.4 columns - 저장할 열 선택 옵션
to_csv에서 columns옵션은 특정 열만 저장하고 싶을때 사용하게 됩니다. 사용법은 저장하고 싶은 열 이름의 리스트를 전달하면 됩니다.
위의 실습과 마찬가지로 코드웍스에서 기본으로 제공되는 exam.csv파일을 가지고 실습을 해보겠습니다. exam.csv파일에는 9개의 column이 있는데, 이 중 no,hour,test 열 데이터만 따로csv 파일로 저장을 하고싶다면, columns옵션을 사용하면 됩니다. 그리고 index없이 데이터만 저장하고 싶기 때문에 본 실습에서는 index를 False로 두겠습니다. 아래는 파이썬 텍스트 코드입니다.
df.to_csv('filename.csv',columns=['no','hours','test'], index=False)아래는 코드웍스 블록 코드입니다. columns에 포함하고 싶은 열 이름의 리스트를 넣은 것을 확인하실 수 있습니다.
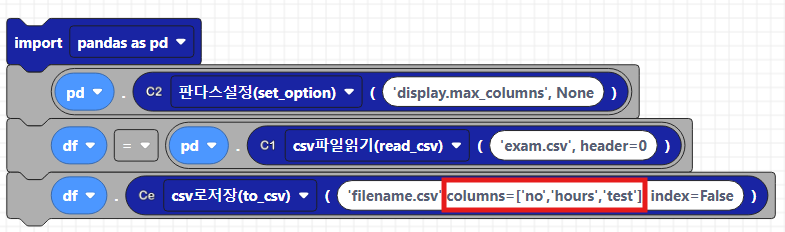
이제 실행 결과를 보면, 왼쪽은 본래 exam.csv데이터이고, 오른쪽은 columns옵션 후의 filename.csv파일 데이터입니다. 우리가 설정한 no, hours, test 열의 데이터만 저장된 것을 확인하실 수 있습니다.


이번 포스팅에서는 데이터분석을 위한 기본인 pandas로 csv 데이터를 데이터프레임 형태로 읽어오고 다시 csv파일로 쓰는 방법을 다뤘습니다. 판다스는 csv파일을 읽어올때, read_csv() 함수를 사용하고, 데이터프레임을 csv파일로 저장할때 to_csv() 함수를 사용하게됩니다. 본 포스팅에서는 각 함수의 가장 많이 쓰이는 네가지 옵션을 실습과 함께 알아보았습니다. 다음 판다스 기초 시리즈 포스트에서는 데이터프레임의 데이터를 파악하는 다양한 판다스 함수들을 다뤄보도록 하겠습니다.
질문이나 추가로 다루고 싶은 내용이 있다면 언제든지 댓글로 남겨주세요!
읽어주셔서 감사합니다 :)
코드웍스 데이터분석 유튜브 무료 강의도 참고해보세요!

'📊 데이터 분석 > 🐼 판다스 pandas' 카테고리의 다른 글
| [판다스 기초] DataFrame 정보 확인 방법 총정리 (5) | 2024.10.28 |
|---|---|
| [판다스 기초] 데이터프레임(dataframe)-생성&출력 (6) | 2024.09.10 |