
안녕하세요 코드웍스입니다.
이번시간엔 판다스의 데이터프레임(dataframe)으로 데이터의 정보를 파악하는 함수들을 소개해드리려고합니다.
pandas에서 데이터분석을 하기전, 데이터 정보를 확인하는 방법에 대한 내용이니 잘 알아두시면 좋을 것 같습니다. 😎

데이터프레임(Dataframe)이란?
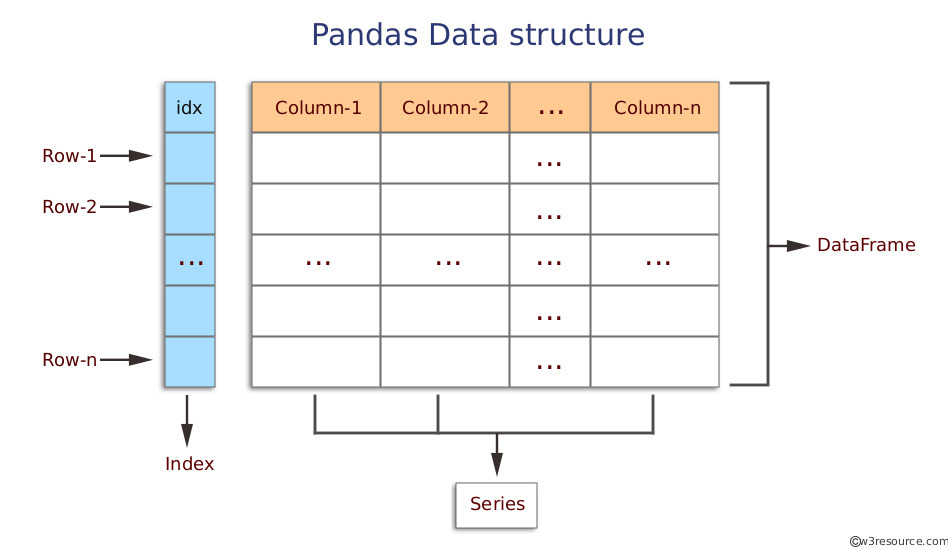
- 데이터프레임(dataframe)은 판다스(pandas) 라이브러리에서 제공하는 2차원 데이터 구조입니다.
- 행과 열로 이루어진 표 형태의 데이터를 다루기 위해 사용됩니다.
기본적인 데이터프레임의 생성에 대한 것은 이전 포스팅에서 보실 수 있습니다.
[판다스 기초] 데이터프레임(dataframe)-생성&출력
[판다스 기초] 데이터프레임(dataframe)-생성&출력
안녕하세요 코드웍스입니다!이번 시간에는 데이터 분석에서 많이 쓰이는 pandas의 dataframe(데이터프레임)을 코드웍스를 활용하여 배워보도록 하겠습니다.목차pandas란?판다스(pandas)는 파이썬에서
codewalks.tistory.com
이제 pandas에서 제공하는 데이터프레임의 기본적인 정보 확인 방법을 할 수 있는 메서드들에 대해 알아보겠습니다.🤔
본 포스팅에서는 인기 만화 포켓몬스터의 전설 데이터를 가지고 실습해보도록 하겠습니다.
데이터셋을 사용하는 방법은 아래에서 설명하고있습니다.
본 실습에서 사용하는 코드웍스 코드는 아래 링크에 있습니다! 😎
코드웍스 데이터셋 아카이브 사용 방법
코드웍스에서는 인공지능이나 데이터분석 교육에 유용한 다양한 분야의 데이터들을 코드웍스 내부적으로 제공하고있습니다. 이번 포스팅에서는 포켓몬스터 전설데이터로 실습을 진행할 것이기 때문에, 그에 따른 사용법에 대해 알려드리도록 하겠습니다.🤔
1. 데이터셋 아카이브 클릭 > 엔터테이먼트 > 두번째 포켓몬스터 전설데이터

이때 오른쪽 끝의 화살표를 클릭하면 데이터셋에 대한 설명이 나오게됩니다. 데이터셋의 feature들과 어느 분야에서 사용하면 좋을지, 데이터셋의 크기가 나타나게됩니다.

이 데이터를 사용하고싶다면,
2. 포켓몬스터 전설데이터 클릭 > 파일명 지정 > 확인
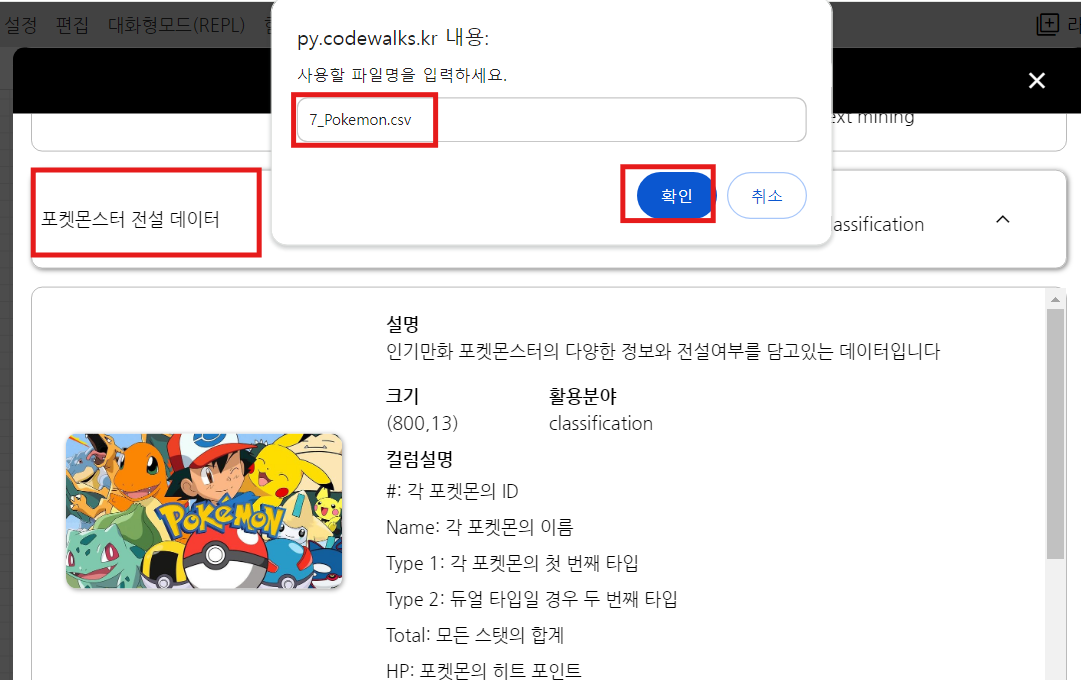
그후 폴더를 클릭하시면, 코드웍스 내부적으로 사용할 데이터가 받아진 것을 확인하실 수 있습니다.
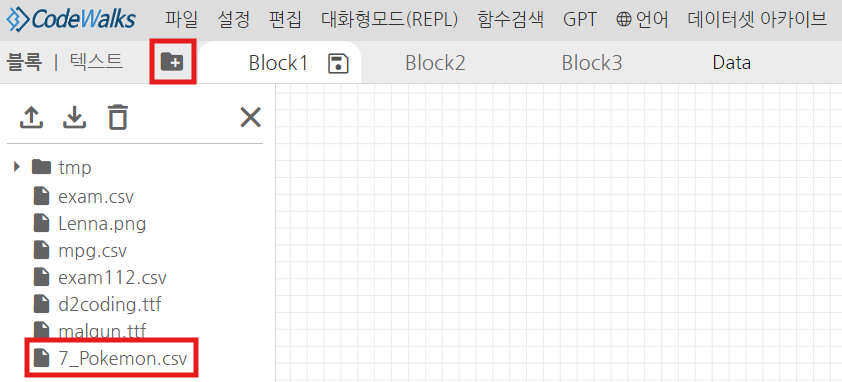
3. 판다스 데이터프레임으로 받아오기
C블록 > 첫번째, 두번째 블록사용
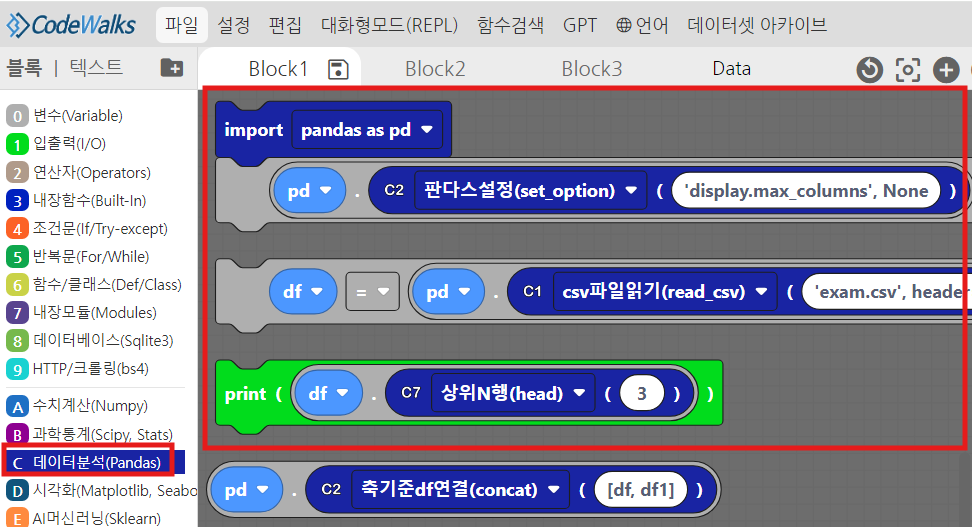
두번째 블록에서 'exam.csv' > '7_Pokemon.csv' 로 변경

실행하면 아래와같이 잘 받아와져서 출력되는것을 확인가능합니다.

1. 기본 정보 확인하기 - info()
- 데이터프레임의 구조를 빠르게 확인하기 위해선 info() 메소드를 사용하는 것이 가장 좋습니다.
- info() : 각 열의 데이터 타입, 결측값 여부, 전체 행 개수 등 전반적인 요약정보를 제공합니다.
import pandas as pd
df = pd.read_csv('7_Pokemon.csv', header=0)
print(df.info())
코드웍스에서는 C7블록에 info를 제공합니다. 실행시켜보시면,

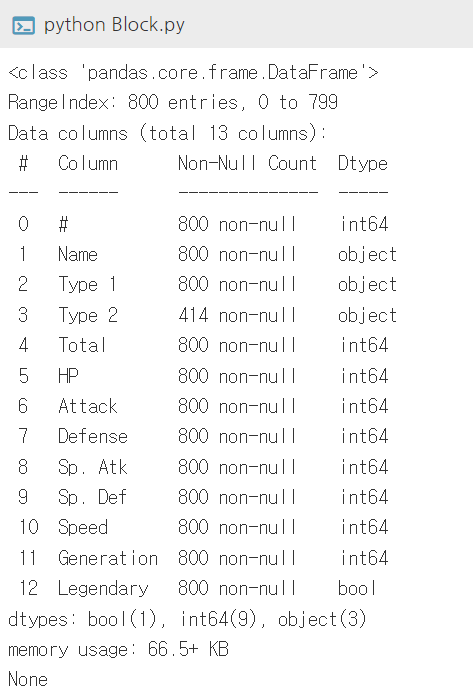
2. 상하위행 미리보기 -head()/tail()
- head(N): 데이터프레임 상위 N개의 행을 반환합니다.
- tail(N): 데이터프레임 하위 N개의 행을 반환합니다.
- head()& tail(): 기본값이 N=5이므로, 상하위 5개의 행을 반환하게 됩니다.
print(df.head()) #상위 5개의 행 추출
print(df.tail()) #하위 5개의 행 추출
코드웍스에서는 head와 tail을 C7블록에서 제공합니다. 실행시켜보시면, 각각 상하위 행이 추출된 것을 확인하실 수 있습니다.
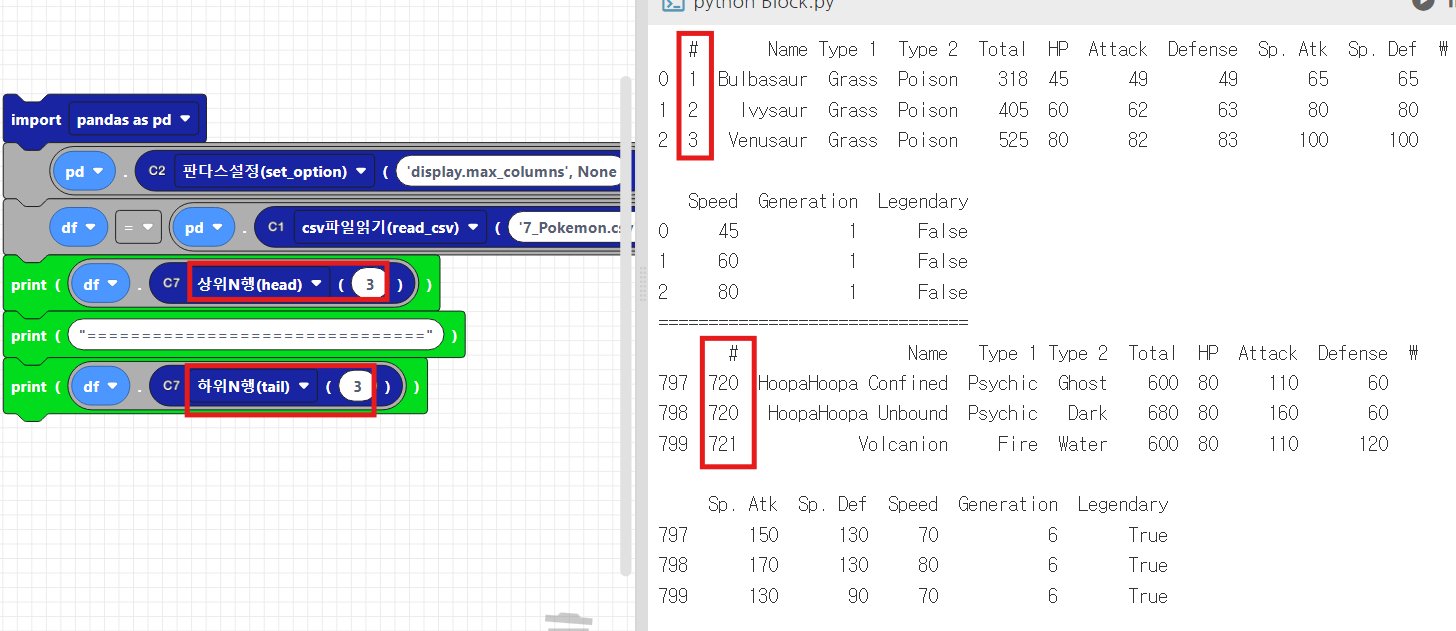
3. 무작위로 샘플 추출하기 - sample()
- 데이터프레임에서 무작위로 행을 선택해서 샘플을 추출하는 함수입니다.
- sample(): 랜덤한 5개의 행 샘플 추출
- sample(N): 랜덤한 N개의 행 샘플 추출
print(df.sample()) # 5개의 랜덤한 샘플 추출
print(df.sample(3)) #3개의 랜덤한 샘플 추출코드웍스에서는 이또한 C7블록에서 제공합니다. 3개의 샘플을 추출해보겠습니다.
랜덤한 id를 가진 샘플이 추출 된 것을 확인하실 수 있습니다.
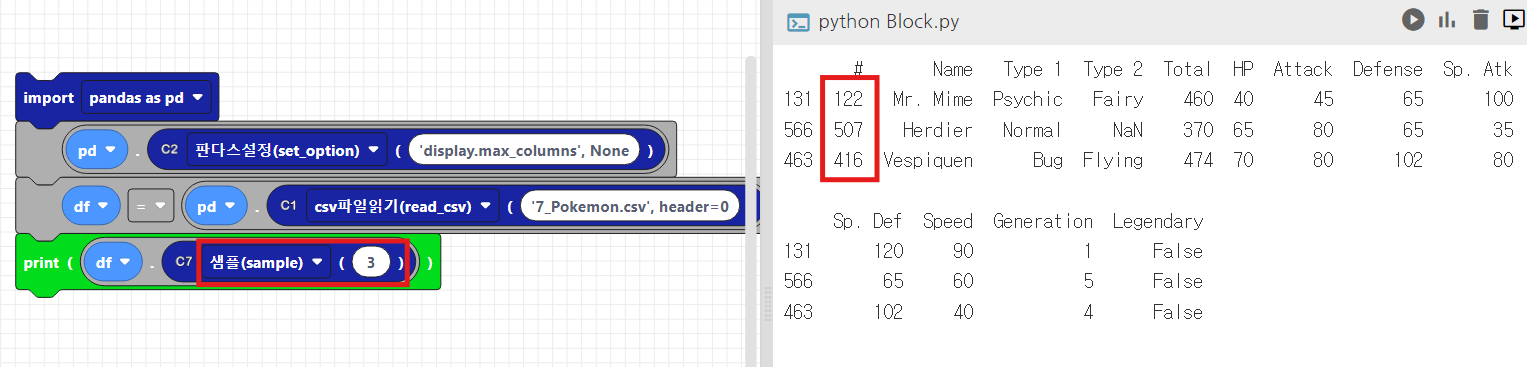
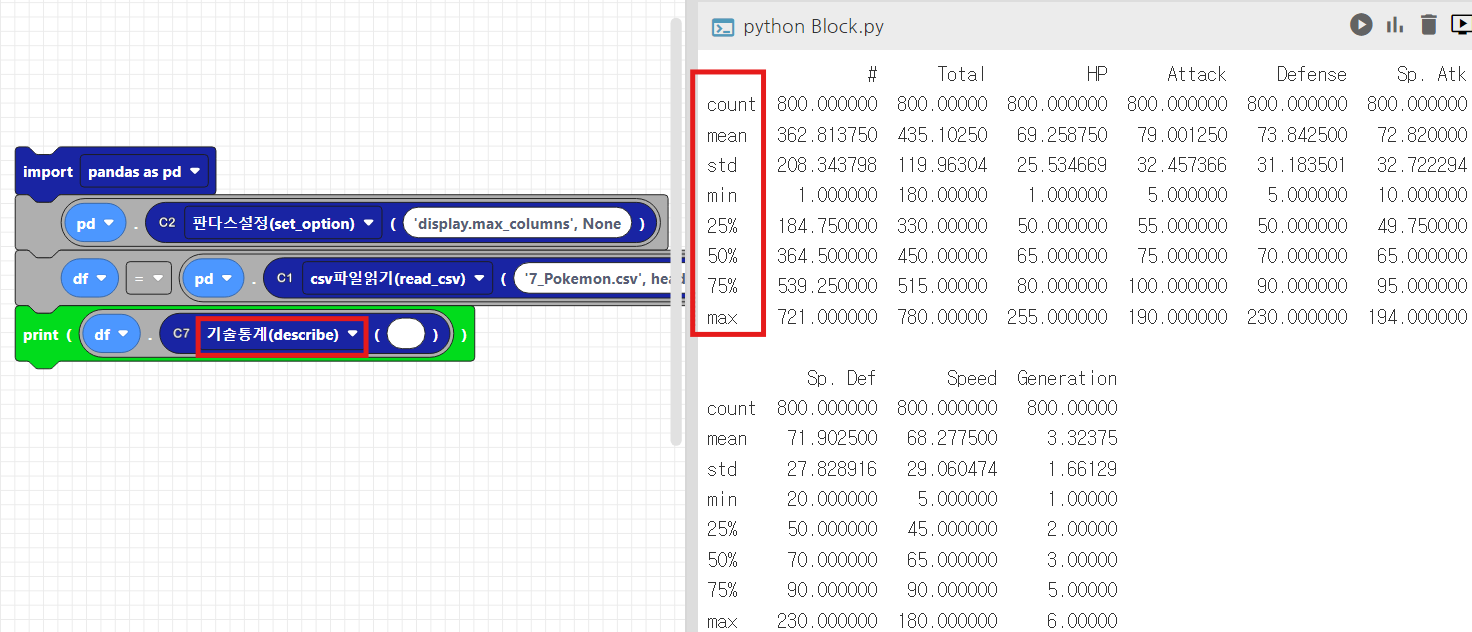
4. 열별 통계정보 확인 - describe()
- describe()는 수치형 열에 대한 기본 통계 정보(평균, 표준 편차, 최소값, 최대값 등)를 제공합니다.
- describe(include = 'all'): 모든열의 통계정보를 확인할 수 있습니다.
print(df.describe()) #수치형 열 통계 정보
print(df.describe(include = 'all')) # 모든 열에 대해 통계 정보
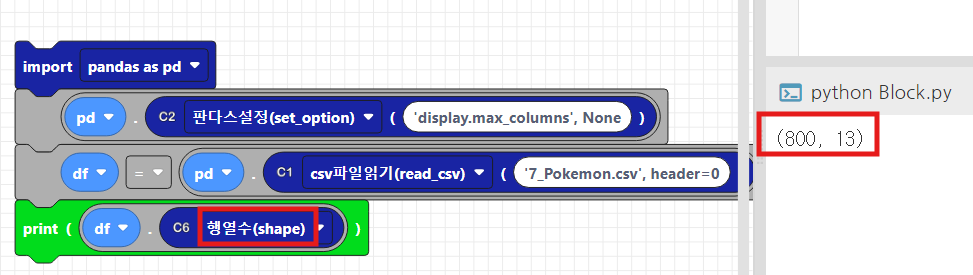
5. 데이터프레임 크기 확인 -shape
- shape는 (행의 개수, 열의 개수) 형태로 튜플을 반환합니다.
- 데이터의 크기를 간단히 확인할 수 있습니다.
print(df.shape)코드웍스에서는 C6블록에서 shape을 제공합니다.
출력해보면, 포켓몬 전설 데이터의 사이즈, 800개의 행, 13개의 열이 출력되는것을 확인하실 수 있습니다.
6. 컬럼과 인덱스 확인 - columns & index
- columns: 데이터프레임의 열 이름을 반환합니다
- index: 각 행을 고유하게 식별하는 "인덱스" 정보를 담고 있는 속성을 반환합니다.
print(df.columns) #칼럼 이름
print(df.index) #인덱스 정보코드웍스에서는 C6에서 columns와 index를 제공합니다.
출력해보면, 데이터프레임의 열(column)이름들이 출력되는 것을 확인하실 수 있습니다. 그리고, index는 행의 인덱스를 출력합니다. index는 RangeIndex(start=0, stop=800, step=1)로 출력되며, 0부터 시작해서 799까지의 정수형 인덱스를 가진다는 것을 의미합니다.

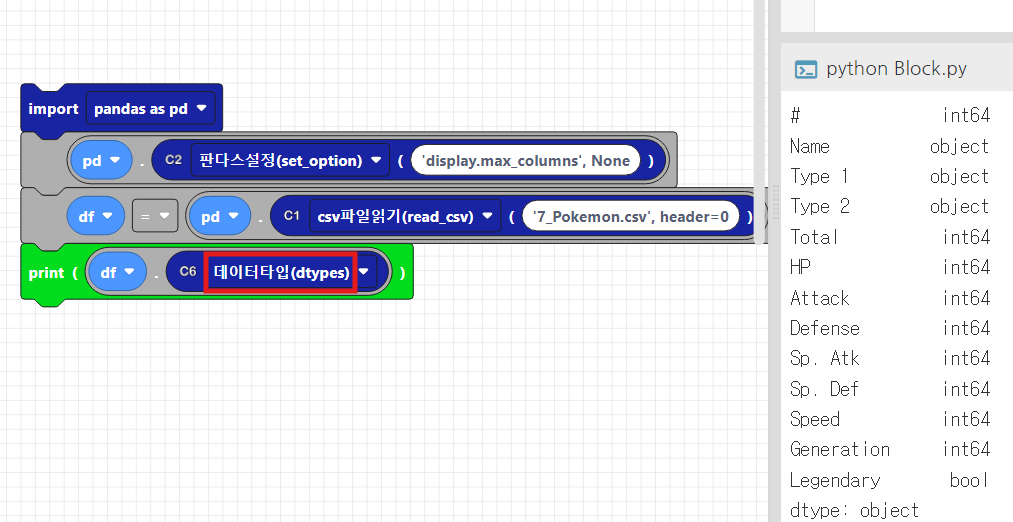
7. 열 데이터 타입 확인- dtypes
- dtypes 속성은 각 열의 데이터 타입을 보여줍니다.
- 이를 통해 각 열이 숫자형인지, 문자열인지 등을 확인할 수 있습니다.
print(df.dtypes)
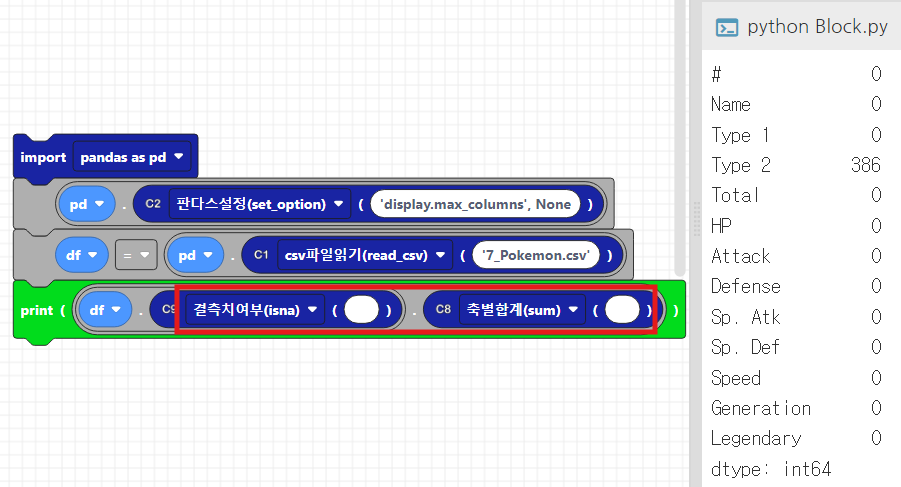
8. 결측값 확인하기 - isna()
- isna().sum(): 결측값의 개수를 확인할 수 있습니다.
print(df.isna().sum())코드웍스에서는 isna()는 C9에서 제공하고, sum()은 C8에서 제공합니다.
출력해보면, 각 열의 결측값이 있는 개수를 출력되는것을 확인할 수 있습니다.
- isna(): 데이터프레임에서 결측값이 있는 위치를 찾을 수 있습니다.
- 결측값 있으면 True, 없으면 False를 반환합니다.
print(df.isna())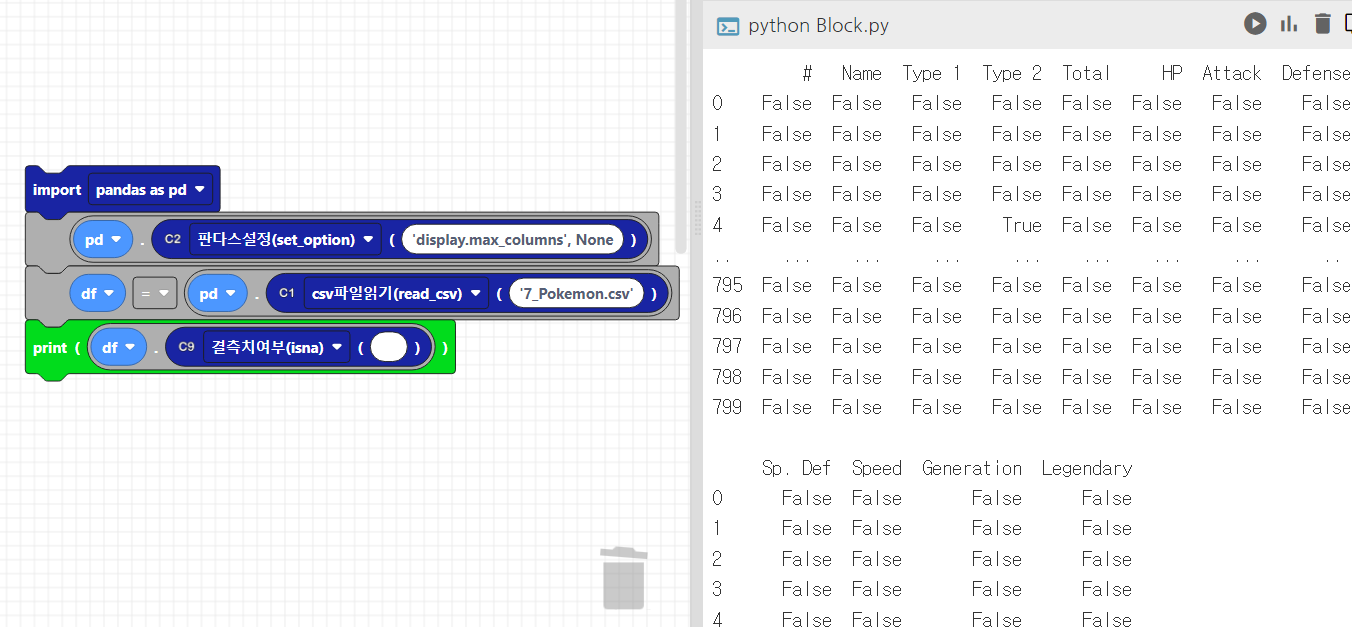
9. 특정 열의 고유값 개수 확인 - value_counts()
- value_counts()는 특정 열에 포함된 각 고유 값의 개수를 계산하고, 이를 내림차순으로 반환하는 함수입니다.
- 주로 범주형 데이터에서 각 값이 얼마나 자주 나타나는지 확인하는 데 사용됩니다.
- 예를 들어, df['열이름'].value_counts()는 특정 열에 있는 값들이 각각 몇 번씩 나타나는지 반환합니다.
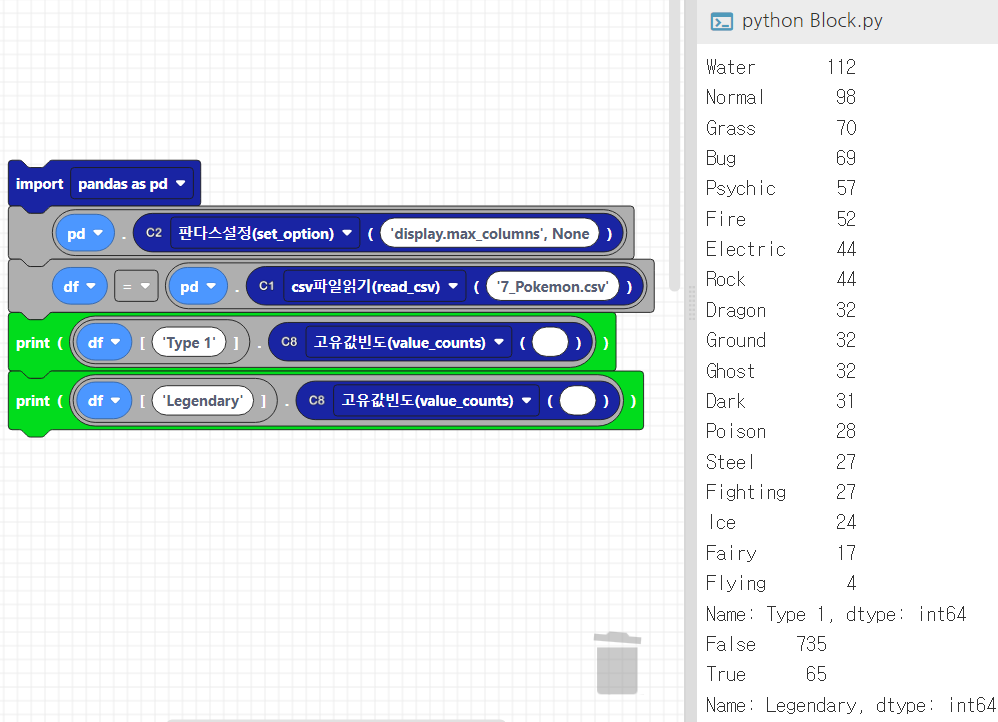
print(df['Type 1'].value_counts()) #type1의 고유값 빈도
print(df['Legendary'].value_counts())코드웍스에서는 value_counts() 함수를 C8블록에서 제공합니다. Type 1의 고유값과 Legendary의 고유값 빈도를 출력해보았습니다. Type1은 Water속성이 112개로 가장 많이 존재하는 것을 알 수 있습니다. Legendary의 True는 전설 포켓몬의 수로 65마리인 것을 확인하실 수 있습니다.
value_counts() 함수에는 여러 옵션들도 제공하는데요, 알아보도록 하겠습니다.
>>주요 옵션<<
- normalize: True로 설정하면 각 값의 개수 대신 상대 빈도를 반환합니다.
- sort: 기본적으로 빈도순으로 내림차순 정렬합니다. False로 설정하면, 나타난 순서대로 나열됩니다.
- ascending: True로 설정하면 오름차순으로 정렬합니다.
- dropna: False로 설정하면 결측값도 포함하여 개수를 셉니다.
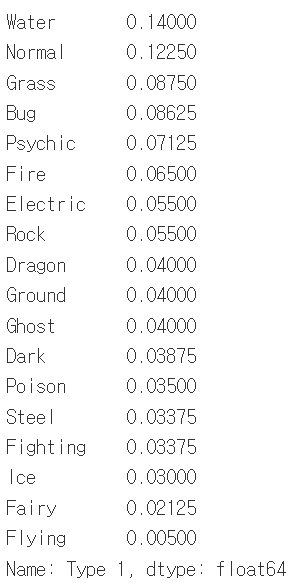
print(df['Type 1'].value_counts(normalize =True)) #상대빈도 반환
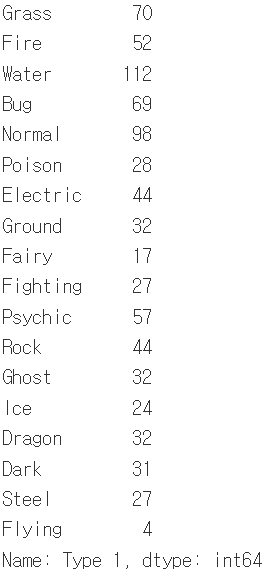
print(df['Type 1'].value_counts(sort = False)) #나타난 순서대로 나열
print(df['Type 1'].value_counts(ascending = True)) #오름차순 정렬
print(df['Type 1'].value_counts(dropna = False)) #결측값도 포함해서 개수 반환아래 접은글은 출력한 결과물입니다.
순서대로 normalize=True, sort= False, ascending=True, dropna=False의 출력 결과물입니다.


10. 고유값 확인 - unique() & nunique()
- unique(): 특정 열이나 시리즈 내의 고유한 값들을 배열 형태로 반환하는 함수입니다.
- nuique(): 특정 열이나 시리즈의 고유 값의 개수를 반환하는 함수입니다. 실제 고유 값들을 배열로 반환하지 않고, 고유 값의 개수만 반환합니다.
df['Type 1'].unique() #Type 1의 고유값 목록
df['Type 1'].nunique() #Type 1의 고유값 개수코드웍스에서는 C8블록에서 제공합니다.(단, nuique()는 블록으로 제공하지 않습니다.)
출력된 것을 보시면, unique()는 type 1에서 나타나는 고유한 값들을 리스트로 반환한 것을 보실 수 있고, nunique()는 고유값의 개수를 출력한 것을 확인하실 수 있습니다.

11. 상관관계 확인 - corr()
- 데이터프레임의 수치형 열들 간의 상관관계를 계산하는 함수입니다.
- 두 변수 사이의 관계 강도를 나타내며, -1에서 1 사이의 값을 가집니다.
- 1에 가까울수록 강한 양의 상관관계(한 변수가 증가할 때 다른 변수도 증가).
- -1에 가까울수록 강한 음의 상관관계(한 변수가 증가할 때 다른 변수는 감소).
- 0에 가까울수록 상관관계가 거의 없음을 의미합니다.
print(df.corr())코드웍스에서는 C8블록에서 corr을 제공합니다.
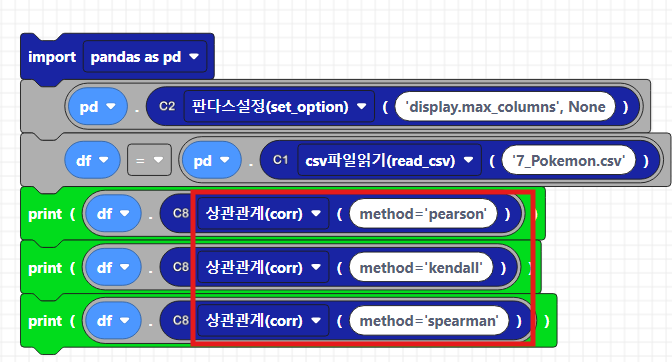
>>주요 옵션<<
method: 상관관계를 계산하는 방법을 지정합니다.
- 'pearson' (기본값): 피어슨 상관계수, 연속형 데이터에 적합.
- 'kendall': 켄달 순위 상관계수, 순위 데이터에 적합.
- 'spearman': 스피어만 순위 상관계수, 비선형 관계나 순위 데이터에 적합.
print(df.corr(method='pearson'))
print(df.corr(method='spearman'))
print(df.corr(method='kendall'))
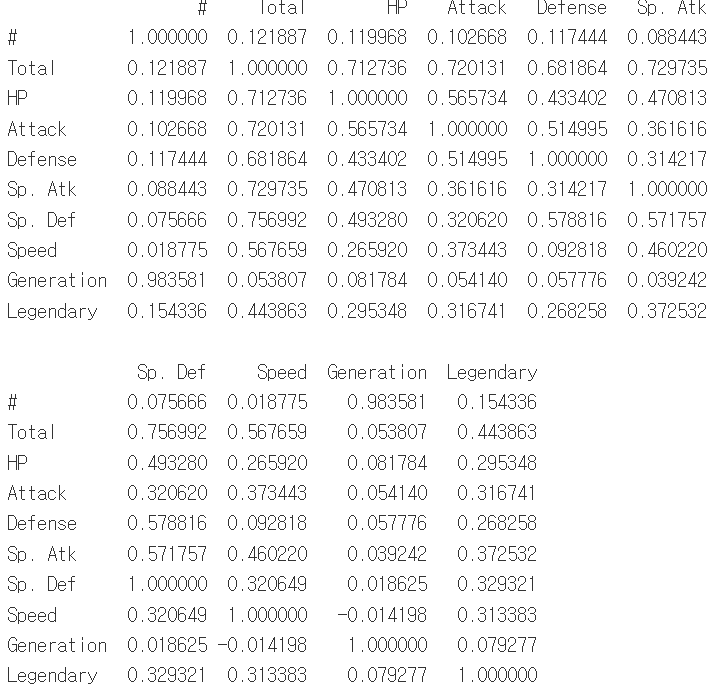
출력된 결과물은 접은글에 있습니다.
pearson(기본값)
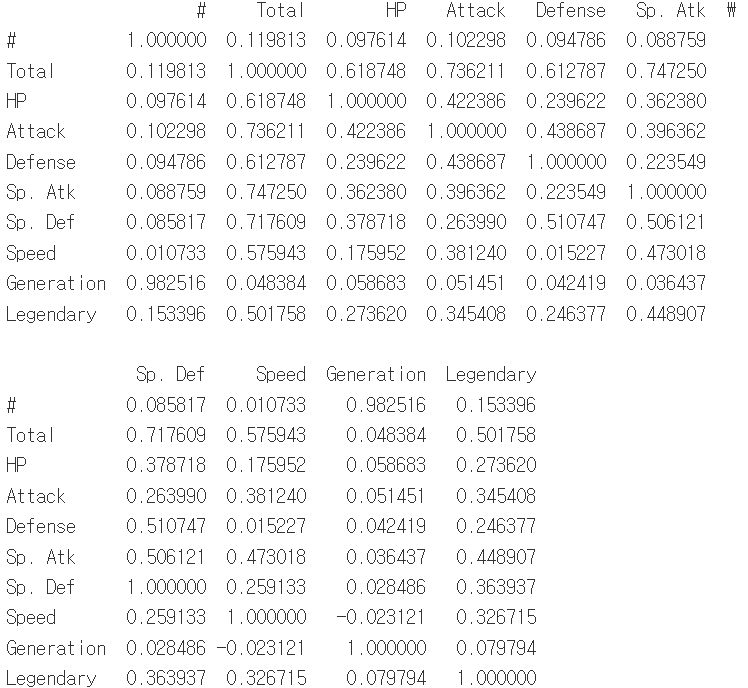
kendall
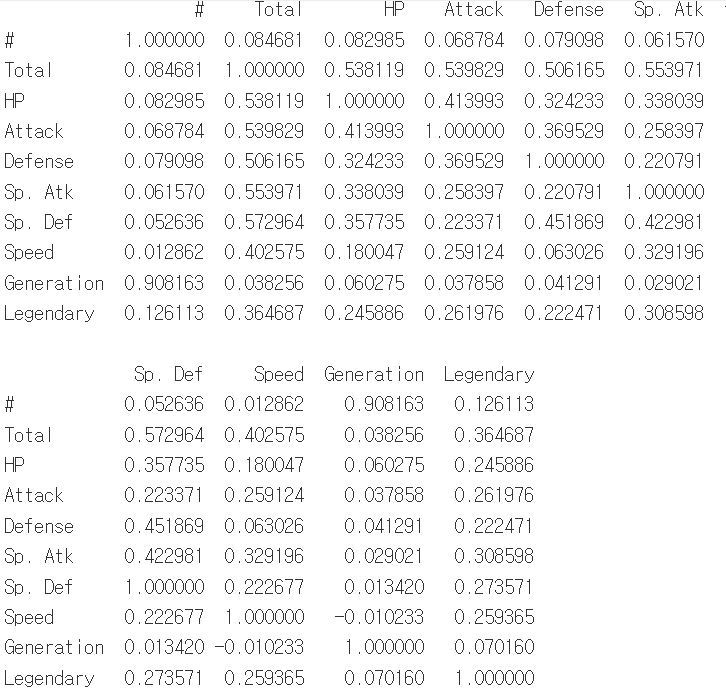
spearmen
이번시간에는 판다스 데이터프레임에서 데이터 정보를 확인하는 다양한 방법에 대해 알아보았습니다.
앞으로 데이터분석을 함에 있어, 중요한 내용이었는데요, 앞으로 다양한 데이터로 분석하는 포스팅도 올릴테니 많은 관심 부탁드립니다.😎
긴글 읽어주셔서 감사합니다.
포스팅이 도움이 되셨다면 좋아요와 구독 부탁드립니다.
궁금한점이나 질문 있으시면 댓글로 남겨주시면 친절히 답변해드리겠습니다.😚
감사합니다.
코드웍스로 진행하는 데이터분석 강의도 들으러 오세요!!

'📊 데이터 분석 > 🐼 판다스 pandas' 카테고리의 다른 글
| [판다스 기초] 데이터프레임(dataframe) csv 파일 읽기 & 쓰기 (10) | 2024.10.01 |
|---|---|
| [판다스 기초] 데이터프레임(dataframe)-생성&출력 (8) | 2024.09.10 |